Spark의 동작 방식
이번 포스팅에서는 Spark가 어떻게 동작하는지 마구 적어보겠습니다.
Spark는 Master Worker Topology로 구성되어 있습니다. 기본적으로 항상 데이터가 여러 곳에 분산 되어 있는 상태이며, 같은 연산도 여러 노드를 걸쳐서 실행되게 되는 점을 고려해야합니다.
과정은 다음의 그림을 보면 알 수 있습니다
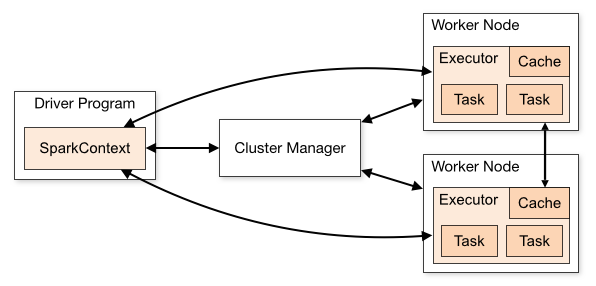
Spark Driver Program
Spark의 Master Node에 해당하는 부분이 바로 Driver Program입니다.
Driver Program은 Spark Context를 단 한 개를 가지고 있는데, Spark Context는 RDD를 만드는 작업을 수행합니다.
텍스트 데이터를 불러오는 Textfile이나 parallelize는 Driver Program의 SparkContext 에서 실행됩니다. Driver Program은 개발자와 프로그램이 상호 작용을 할 수 있는 공간이고, 실제로 분산 환경에서 동작하는 것은 Worker입니다.
일반적으로 Driver Program은 RDD를 생성하는 것 뿐만 아니라 Worker Node에게서 사용가능한 Executer수와 CPU cores 수를 확보하고 메인 프로세스를 실행시키는 동작을 수행합니다. 그리고 Transformation과 Action에 대한 데이터를 저장하고 Worker에게 전달하는 작업을 수행합니다.
Driver Program은 Worker Node와 통신이 필요한데 그 이유는 다음과 같습니다.
- Task를 Executer에게 전송해야 합니다.
이러한 이유로 스케줄링과 자원 할당을 원활하게 하기 위해서 Driver Program은 Cluster Manager라는 중간 단계를 두고 Worker Node와 통신합니다.
Driver Program은 한 개의 애플리케이션이지만, Cluster Manager는 여러 개로 나누어 질 수 있습니다. 일반적으로 Yarn, Mesos, kubernetes를 사용합니다.
Spark Cluster Manager
Cluster Manager는 Worker Node에 자원을 할당하거나 작업을 스케줄링하는 역할을 수행합니다.
Spark Worker Node
예제에서는 데이터를 print하는 액션을 취하는 부분이 있었는데, 여기서 결과로는 보이지 않는 문제가 발생했습니다. 이 이유는 바로 Action을 처리하는 노드가 Worker 노드이기 때문에 Driver Program에 해당하는 로컬환경에서는 해당 명령이 실행되지 않기 때문입니다.
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("study")
sc = SparkContext.getOrCreate(conf=conf)
a = sc.parallelize(['test1','test2','test3'])
a.map(lambda x:print(x))
a.count()
위 코드에서 Action이 실행되면 분명 Transformation인 map도 실행이 되어야 하는데 실제 결과는 a.count()의 결과인 3이 리턴되고 끝나는 것을 확인 할 수 있습니다.
Driver Program과 Worker Node가 소통하는 방법으로는 중간에 Cluster Manager라는 단계를 두고 소통합니다.
수행되는 작업의 스케줄링과 자원관리를 도와준다.
Driver Program은 모든 프로세스 조직하고, 메인 프로세스를 실행, SC생성, RDD생성, Transformation, Action 저장, Worker에 전송
Worker Node의 Excuter는 연산 수행, 데이터 저장, DP에 전송, Task 실행 후 연산 결과 DP에 전송, 연산 결과를 저장하기위한 캐시도 있음
DP -> sc 생성(spark application) -> 클러스터 매니저에 연결 -> 자원 할당 -> 클러스터에 있는 노드들의 익스큐터 수집 -> 연산 수행 후 데이터 저장 -> sc가 익스큐터에게 task 전송 -> task 연산 결과를 다시 드라이버에게 전달