Hash
Hash란?
Hash란 다양한 크기의 데이터를 고정적인 크기를 가진 값으로 매핑하는 함수입니다.
즉 매핑이 이루어지기 전 값이 key라면 Hash(key)의 결과로 도출되는 것이 값(value)입니다.
\[Hash(key) = HValue\]이 방식을 이용한 예시와 순서에 대해 공부해보겠습니다.
HashTable
Hash 방식을 이용하여 자료구조를 구현해낼 수 있습니다. 바로 Map과 같은 자료구조에서 사용 될 수 있는데, 그 순서는 다음과 같이 그려 볼 수 있습니다.
다음의 그림에서는 정수 혹은 문자열이나 파일과 같은 데이터를 기반으로 어떻게 데이터를 탐색 및 저장하는지에 대한 일련의 과정을 볼 수 있습니다.

- 데이터를 Hash Function의 인자로 넣어 Hash Value를 얻습니다.
- Hash Value를 Index를 얻을 수 있는 함수의 인자로 넣어 배열에 접근 할 위치인 Index를 얻습니다. [ 나머지를 이용하는 방법을 주로 사용 ]
- Index를 이용하여 배열에 접근하여 값을 읽거나 저장한다.
이렇게 Hash라는 방법을 이용하여 배열의 사이즈가 저장되는 데이터에 비해 상당히 크다는 가정하에 평균 접근 시간이 O(1)인 자료구조를 만들 수 있습니다.
이 점을 기반으로 HashTable을 구현해보겠습니다.
HashTable 구현
class HashObj:
def __init__(self,hashValue,value):
self.hashValue = hashValue
self.value = value
def is_equal(self,hashValue):
if self.hashValue == hashValue:
return True
else:
return False
def getValue(self):
return self.value
def getHash(self):
return self.hashValue
class Hash:
def __init__(self,size=17):
self.HashMinimum = 100000000
self.size = size
self.arr = [[] for i in range(size)]
def setEqualHashSize(self,hashValue):
return hashValue * (self.HashMinimum//hashValue +1 )
def hashCode(self,key):
return self.setEqualHashSize(sum(list(map(lambda x:(x[0]+1)*ord(x[1]) ,enumerate(key)) )))
def hashFunction(self,key):
return self.hashCode(key) % self.size
def save(self,key,value):
# self.arr[self.hashFunction(key)] = self.hashCode(key)
self.arr[self.hashFunction(key)].append(HashObj(self.hashCode(key),value))
def getArray(self):
return self.arr
def find(self,key):
key_hash = self.hashCode(key)
for hashobj in self.arr[self.hashFunction(key)]:
if(hashobj.is_equal(key_hash)):
return hashobj.getValue()
return 'None'
HashTable을 통해 데이터를 추가와 조회하는 경우만을 가정하여 다음과 같은 코드를 작성했습니다.
실제로는 Hash Function은 동일한 크기의 Hash값을 리턴하는 것을 다른 방식으로 구현되어 있겠지만 저는 임시적으로 100000000을 넘는 값까지 곱하는 방식으로 간략하게 만들어보았습니다.
위의 값 이상의 값이 key로 주어진다면 자릿수 고정은 안되겠지만 일단은 key-value 형식을 구형해보았습니다.
결과를 한번 확인해보겠습니다.
for i in range(0,50):
a.save(str(i),'value'+str(i))
print(list(map(lambda x:len(x),a.getArray())))
# [6, 1, 2, 2, 2, 5, 2, 5, 3, 1, 4, 7, 0, 3, 1, 4, 2]
0부터 49까지의 숫자를 문자로 바꾸어 HashTable에 저장해보니 다음과 같은 결과가 나왔습니다. HashTable을 이용한 자료구조에서는 Index가 고르게 나오는 것이 효율적이라고 말할 수 있습니다.
예를 들어 위의 결과에서 11번째 위치에는 7개의 요소가 포함되어 있기 때문에 탐색하는데 7개의 요소를 확인해야합니다. 만약 50개의 요소가 한 key에 모여있다면 어떻게 될까요?
최악의 상황을 만들어봅시다!
for i in range(0,350):
if(a.hashFunction(str(i)) == 0):
a.save(str(i),'value'+str(i))
print(list(map(lambda x:len(x),a.getArray())))
# [50, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
저장 된 데이터가 50개지만 한 인덱스에 모여있는 것을 볼 수 있습니다. 그렇다면 우리는 특정 키에 대한 값을 찾기 위해서는 50번의 반복문을 수행해야합니다.
이 경우가 최악의 탐색 효율인 O(n)의 예시입니다.
즉 좋은 HashTable을 만들기 위해서는 좋은 hashFunction을 만들어야하고, 좋은 hashFunction은 Index를 고르게 분포시킬 수 있는 알고리즘이어야 합니다.
구현해놓은 HashTable은 이미 충돌에 대한 대처를 해 놓은 상황이지만 충돌에 대해 이야기해보겠습니다.
충돌
HashTable을 이용하다보면 문제가 발생합니다. 왜냐하면 제한된 배열의 갯수를 이용하는한 겹치는 Index를 가지는 데이터가 있기 마련이기 때문이죠.
위의 코드에서는 “3”과 “10”은 0인덱스를 가지는 데이터입니다. 그러면 같은 위치의 배열에 들어가게 되죠. 만약 데이터를 덮어쓴다면 데이터의 손실이 일어나고 그렇다고 무시할 수 없습니다.
충돌에 대처하는 방법은 두가지가 있습니다.
다음 인덱스에 넣자
다음의 그림과 같은 방식과 같이 작동하는 방식입니다.
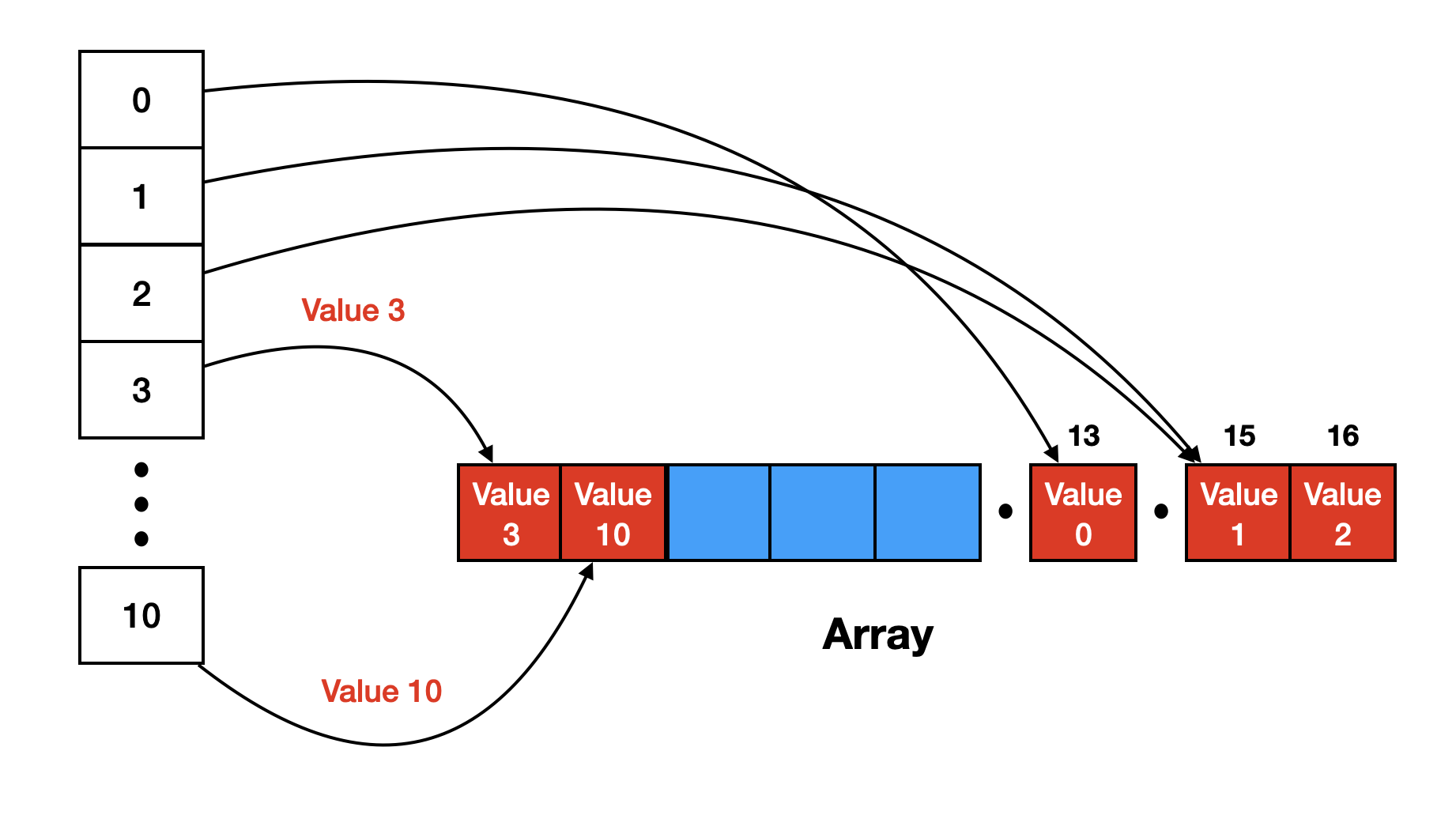
이러한 방식을 이용하면 해당 데이터에 맞는 인덱스를 찾아 배열에 접근했을 때 만약 찾고있는 값이 아니라면 다음 인덱스를 탐색하는 방식으로 작동합니다.
저는 여기서 2가지 문제점을 발견할 수 있습니다.
- 어디까지가 이 키의 값이지?
- 만약 배열이 가득차거나 접근한 인덱스가 마지막 요소라면?
1. 어디까지가 이 키의 값이지?
hashFunction을 통해 Index값으로 변형시켰고 해당 Index에 값을 채워넣었다면 데이터는 순서대로 저장되지 않습니다. 더구나 배열의 크기가 작다면 저장 중 다음 노드가 채워져 있을 확률이 높겠죠.
데이터 소실을 방지하기 위해서는 그 위치를 넘어서라도 데이터를 저장해야합니다. 그렇게 되면 어디까지가 이 키를 기반으로 접근 한 범위인지 알 수 없게 되면서 O(n)번 탐색하는 경우도 생길 확률이 높습니다.
2. 만약 배열이 가득차거나 접근한 인덱스가 마지막 요소라면?
저장하는 데이터가 많아질수록 배열이 가득 찰 확률은 높습니다. 더구나 마지막 요소에 접근했을 경우에는 다음 요소를 찾을 수 없게 됩니다.
이 경우에는 배열을 크게 확장하여 resize하는 방식을 수행합니다. resize는 배열을 크게 늘리고, 들어온 데이터를 다시 위치시키면서 배열을 키워나가는 방법으로 이렇게하면 배열을 동적으로 크게 만들 수 있으므로 배열이 가득차는 문제를 해결 할 수 있습니다.
배열에 배열을 구현하자
이 방법은 다음과 같이 그림으로 표현할 수 있습니다.
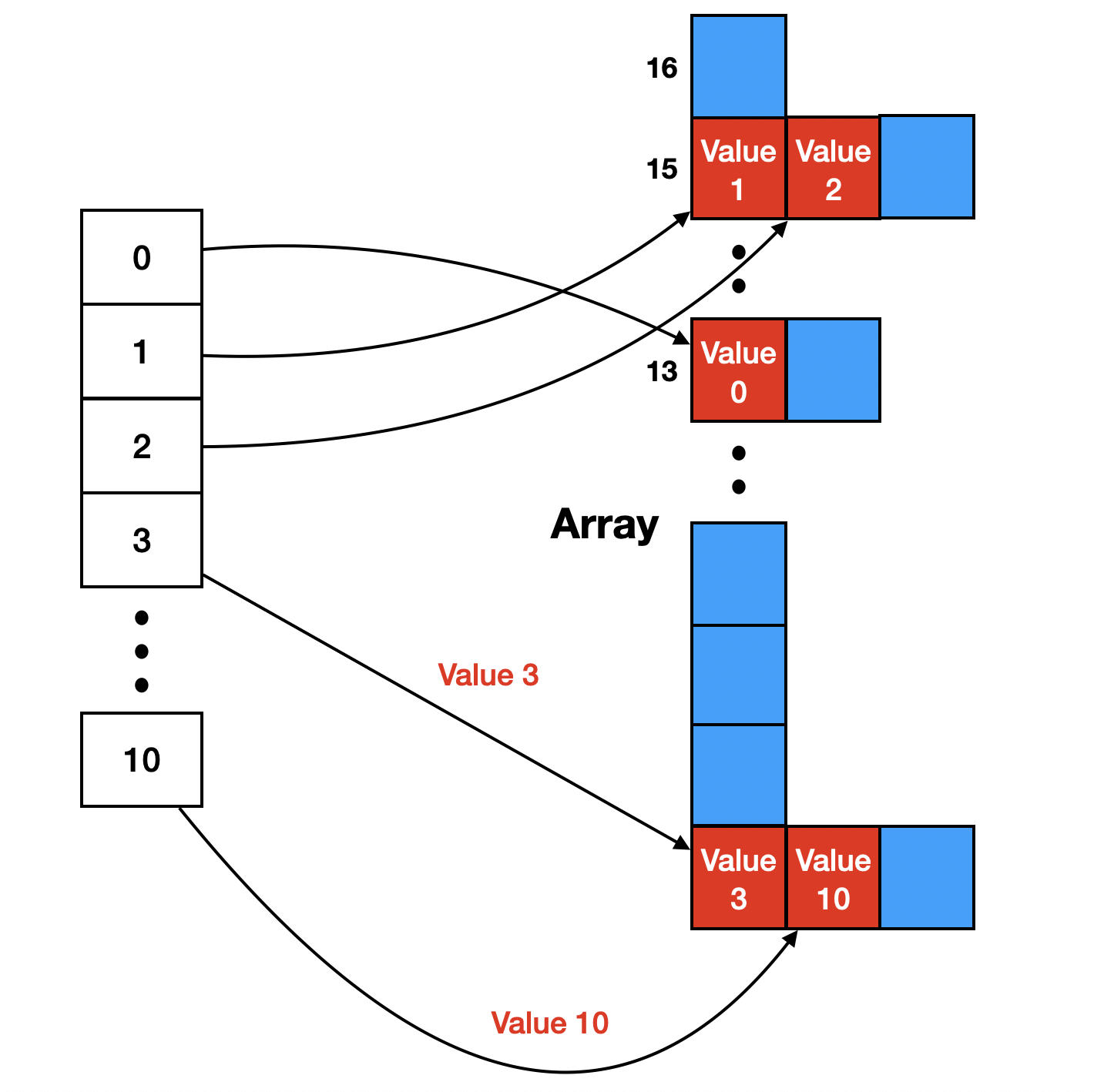
Index로 접근했을 때 요소가 리스트라면 만약 해당 Index에 값이 있더라도 다음 인덱스에 추가하면 기존의 배열에 영향을 주지 않고도 HashTable 구현이 가능해집니다.
일반적으로 이 과정에서 사용하는 리스트는 LinkedList를 사용합니다. 이유는 간단히 예측할 수 있는 요소를 탐색하는 방식은 전체 요소를 탐색하는 방식으로 진행되며 삽입과 삭제의 시간복잡도를 줄이기에는 LinkedList가 적합하기 때문입니다.