Hadoop
토이 프로젝트를 시작하기 전 Hadoop 환경을 구축하기 위해 포스팅을 남깁니다.
이전에 간략하게나마 MapReduce와 HDFS에 대해 설명을 적었지만, 다시한번 공부를 해보고자 합니다.
HDFS 환경을 로컬에 직접 구현하는 것보다 잘 구현되어 있는 도커 이미지를 가져와서 환경을 구축하고 그 내부의 설정 값을 하나씩 알아보겠습니다.
언젠가 정말 한번은 이 시간을 가져야 한다고 생각을 했었습니다. 드디어 하네요.
Hadoop은 코끼리 모양을 하고 있는 데이터의 분산 저장 및 처리를 도와주는 프레임워크입니다. 크게는 두 가지로 구분 할 수 있습니다.
이번에는 그 중 HDFS를 알아보겠습니다.
HDFS
등장 배경
HaDoop File System의 약자로 파일을 통해 여러 서버에 데이터를 분산 저장하고 또 불러오는 방식을 제안하는 시스템입니다.
HDFS는 Master - Slave 구조로 동작하는 데이터 분산 저장 스토리지 입니다.
기존에 사용하던 RDB는 대부분 한 서버에서 동작하는 스토리지였습니다. ( 요즘은 그렇지 않을 수 있습니다만 )
그 외에도 스키마에 종속적인 데이터 저장 방식과 비슷한 이야기지만, 정규화 된 테이블을 통해 데이터의 명확한 구조를 설계하는 등의 작업이 필요하며 ACID의 특징을 가지고 있습니다.
하지만 데이터의 특징이 달라지면서 다양한 스토리지 형식이 등장하기 시작합니다.
비정형 데이터를 잘 보관하기 위해 사용되는 NOSQL, 그리고 대규모의 데이터를 저장하기 위해 사용되는 HDFS, 어차피 파일을 저장한다면 오브젝트 형식으로 저장하는 Objective Database 등도 등장했습니다.
HDFS란?
HDFS에 대한 글을 해석한 내용을 기반으로 정리하겠습니다.
HDFS는 파일을 분산 된 환경에서 저장하고 불러 올 수 있도록 설계 된 스토리지 입니다. 여기서 분산 된 환경은 클러스터 개념으로 일반적으로는 서버 개념으로 생각 할 수 있습니다.
HDFS는 NameNode와 DataNode로 이루어져 있습니다. 일반적으로 NameNode는 하나만 존재하고, SecondaryNameNode라는 별도의 노드가 하나 존재합니다.
여기서 SecondaryNamenode는 1버전에서 주로 사용되던 이름이고, 2버전, 3버전으로 업데이트 될 때마다 새로운 기능이 추가 된 여분의 Namenode가 등장합니다.
그리고 DataNode는 1개 이상으로 존재 할 수 있습니다. 위 글에서는 클러스터와 노드를 개념적으로 나누어서 이야기 했습니다만, 일반적으로 1개의 클러스터에는 1개의 노드가 할당 된다고 말합니다.
HDFS는 분산 파일 저장을 수행하므로, 데이터를 받으면 정보를 블럭의 개념으로 나누고 각기 다른 클러스터 ( = 노드 )에 분배하는 방식으로 파일을 저장합니다.
이 개념을 잡고 NameNode와 DataNode를 알아보겠습니다.
1. NameNode
NameNode는 데이터가 어디에 저장되어 있는지, 그리고 어느 클러스터 ( = 노드 )에 저장되어 있는지를 추적하고 있고, 해당 데이터에 대한 정보를 취합하여 볼 수 있도록 정보를 제공해줍니다.
우리가 HDFS를 통해서 특정 파일을 저장하게 된다면, 파일은 특정 크기의 블럭으로 분할하게 되고 그 블럭을 클러스터에 저장하면서 관련한 내용을 Namespace에 저장하게 됩니다. 하지만, 어느 글에서는 Metadata를 저장한다고 합니다.
무엇이 Metadata인지, 무엇이 Namespace인지 궁금하여 검색 한 결과 링크에서 지식을 얻을 수 있었습니다.
파일 이름이나 계층의 구조등을 저장하는 것이 Namespace이고 파일의 주인/ 권한/ 블록 사이즈/ 크기등을 저장하는 곳이 Metadata라고 합니다.
즉 NameNode는 Namespace를 관리하고, Namespace에는 파일의 경로와 Metadata를 가지고 있습니다.
NameNode는 Namespace를 이용해서 파일 열기/ 파일 닫기/ 이름 바꾸기등의 동작을 수행 할 수 있습니다. 위 글에서는 파일 열기/닫기 라는 표현을 사용했지만, 내용을 읽는 것이 아닌 Metadata를 이용해서 파일의 내용을 읽을 수 있도록 버퍼를 여는? (파일의 포인터를 만드는?) 정도의 수행이라고 생각됩니다.
NameNode는 결국 파일에 대한 정보를 전반적으로 관리하고 있다고 생각하면 될 것 같습니다. 물론 그 과정에서 영속성을 보장하기 위한 snapshot을 저장 할 필요가 있습니다. HDFS의 동작을 순차적으로 저장하고있는 editlogs 파일을 저장함으로써 현재의 상태를 주기적으로 갱신합니다.
또한, DataNode에 대한 정보를 계속해서 갱신합니다. 동작을 수행하던 중 특정 DataNode에 대해 동작하지 않음을 확인하면 얼마든지 다른 클러스터에게 해당 Task를 재할당 할 수 있습니다.
하지만 이런 동작을 수행하기 위해서는 현재 DataNode가 동작이 가능한지에 대해 알아야합니다. 그때 등장하는 개념이 Heartbeat입니다.
DataNode는 ( 초기 설정 상 ) 3초마다 한 번씩 Heartbeat를 NameNode로 보내고 NameNode가 10초 안에 이 통신을 받지 못하면 해당 DataNode는 사용하지 못한다고 판단합니다. 뿐만아니라 block report도 보내줍니다.
block report에 대한 설명은 다음과 같이 정의되었습니다.
A blockreport is a list of all HDFS data blocks that correspond to each of the local files, and sends this report to the NameNode.
Each DataNode create and send this report to the NameNode:
when the DataNode starts up (It scans through its local file system)
at specified interval ?
A Blockreport contains the list of data blocks that a DataNode is hosting. Each block has a specified minimum number of replicas.
간단히 말하면 해당 DataNode가 가지고 있는 block에 대한 리스트라고 볼 수 있습니다.
NameNode는 이러한 block report를 기반으로 Namespace를 최신화 합니다. NameNode에는 Secondary NameNode와 Active/Standby NameNode와 같은 개념이 있지만 다음에 알아보도록 하겠습니다.
2. DataNode
데이터가 실제로 저장되는 공간이고, 또는 처리되는 공간입니다. 데이터를 저장 할 떄 n개의 block으로 데이터를 분할하여 각기 다른 DataNode에 저장하게 됩니다.
중요한 점을 짚으면, 클라이언트가 데이터를 조회 할 때 NameNode를 통해 데이터를 읽는 것으로 생각 할 수 있습니다. 하지만, 실제로는 클라이언트는 DataNode에서 직접 데이터를 읽습니다. 그 과정에서 NameNode는 그저 파일이 저장되어있는 공간에 대한 정보만 클라이언트에게 제공하게 됩니다.
heartbeat와 block report는 NameNode 부분에서 설명했기 때문에 넘어가도록 하겠습니다.
HDFS는 무엇이 다른가?
자세한 특징을 알아보기 전에 HDFS는 파일을 저장한다는 개념부터 잡고 갑니다. Schema에 저장 된 행/열의 특정 형태를 유지하고 있지 않고, NOSQL처럼 JSON과 같이 텍스트 형식으로 이루어져 있지 않습니다. ( 물론 NOSQL 또한 Document 저장을 기반으로 할 수 있지만 )
HDFS는 파일을 저장합니다. 그게 Binary든 Text든 상관없죠.
그러면 특징을 알아보겠습니다. 이 내용은 HADOOP에 대한 공식 문서를 참고로 쓴 다음의 포스팅의 특정 부분을 해석 한 설명입니다. Hadoop에 대한 글
1. Fault tolerance and reliability ( 내결함성과 신뢰성 )
“HDFS는 파일 블록을 복제하고 대규모 클러스터의 여러 노드에 저장할 수 있어 내결함성과 안정성을 보장합니다.”
HDFS의 파일을 block으로 분할하여 각기 다른 노드에 저장하는 방식을 통해 특정 데이터가 변형되거나 손상되었을때도 다른 block의 데이터가 남아있기 때문에 내결함성과 신뢰성을 가지고 있다고 말하는 듯 합니다. 하지만 한 가지 더 알아야 하는 부분이 있습니다.
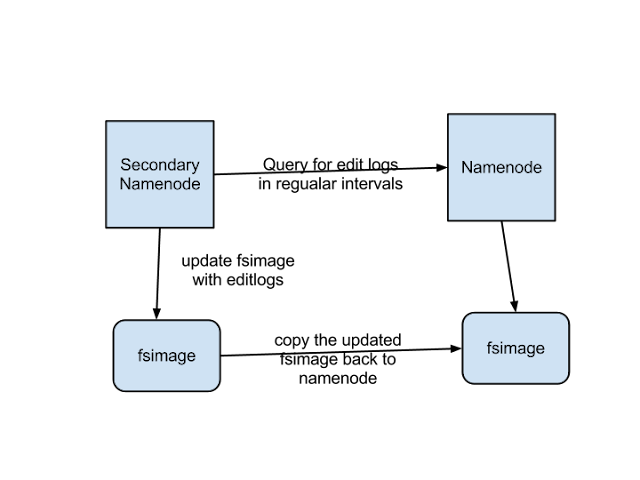
바로 Secondary NameNode입니다.
Secondary Namenode는 사실 Namenode를 대신하기 위해 존재하는게 아닙니다. 자세한 내용은 다음의 링크를 통해 알 수 있습니다. Secondary NameNode란?
저는 위의 내용을 요약하여 말씀드리겠습니다.
1.1 영속성을 위해 Snapshot을 업데이트 해야한다.
HDFS를 사용하게 되면 File System를 최신화하기 위해 다음의 두 가지 파일을 만들게 됩니다.
첫 번째는 fsimage입니다.
fsimage의 설명은 다음과 같습니다.
“Its the snapshot of the filesystem when namenode started”
NameNode가 시작 할 때의 snapshot입니다. NameNode를 시작하게 된다면, 가장 최근 시점의 파일 시스템의 읽기 전용 복사본 ( 즉 snapshot )을 따라 데이터를 복원하게 됩니다. 이러한 이유로 NameNode를 재시작하게 되면 fsimage를 최신화 해야 합니다. 그래야 NameNode가 다시 실행 되었을 때 종료하던 시점의 형태가 유지 될 테니까요.
그때 사용 되는 것이 바로 두 번째인 edit logs입니다.
edit logs의 설명은 다음과 같습니다.
“Its the sequence of changes made to the filesystem after namenode started”
NameNode가 실행 된 이후 파일 시스템에서 일어난 변화의 연속적인 로그라는 것이 설명입니다. 즉 처음부터 차례대로 동작을 수행하면 현재 상태의 파일 시스템에 도달한다는 것이 보장 된 로그입니다. 이 edit logs를 만드는 기준은 Datanode에서 보내는 block report입니다.
NameNode를 재시작하기 위해 종료를 하게 되면 계속해서 쌓아 온 edit logs를 통해 fsimage를 만듭니다. 자세하게 말하면 현재 NameNode가 실행되었던 시점의 fsimage부터 현재 파일 시스템의 형태가 되기 까지의 모든 변화를 포함하여 다음 NameNode가 실행 될 때 반영 될 fsimage를 새로 만들어 낸다고 말 할 수 있습니다.
그리고 이러한 fsimage를 덮어 씌우는 방식으로 NameNode는 영속성을 유지 할 수 있습니다.
1.2 그러면 언제 fsimage를 만들어야 하지?
fsimage를 만드는 것을 무한정으로 미루는 것은 힘듭니다. 왜냐하면 Namenode가 10년간( 극단적으로 ) 동작을 수행하다가 재실행을 하게 된다면, Namenode가 가진 editlogs는 10년동안 HDFS에서 동작했던 모든 로그를 담게 됩니다.
상용서비스라면 그 양은 엄청난 크기 일 것이고, 그 로그를 통해 fsimage를 만들어야 하는 서버는 큰 오버헤드를 갖게 됩니다. 뿐만아니라 정상적인 재실행이 아닌 특정 오류로 인해 editlogs가 손상된다면, 대규모의 데이터 손실이 일어 날 수 있습니다.
그래서 HDFS는 주기적으로 fsimage를 만드는 활동을 합니다. 하지만 Namenode가 만들기에는 어려움이 있습니다. 동작을 수행하면서 editlogs를 쌓아야 하는 Namenode의 입장에서 editlogs를 fsimage를 갱신하는 일을 수행하다가 다른 동작에 문제가 발생 할 수 있으니까요.
1.3 주기적으로 editlogs를 받아 fsimage를 만들어 fsimage를 교체
SecondaryNamenode가 이런 일을 대신 수행해줍니다. 가장 먼저 특정한 시간마다 Namenode를 복사한 SecondaryNamenode에서 editlogs를 가지고 자신의 fsimage를 업데이트 합니다. 그 후 fsimange를 Namenode의 fsimage와 교체하는 방식으로 Namenode에게 부하를 주지 않고 문제를 해결합니다.
2. High availability ( 고가용성 ) - HA
“앞에서 언급했듯이 노트 간 복제로 인해 NameNode 또는 DataNode에 장애가 발생하더라도 데이터를 사용할 수 있습니다.”
여기서 DataNode의 경우에는 1개 이상의 DataNode를 사용할 수 있으니 이해 할 수 있지만, NameNode의 장애에 대해서는 어떻게 장애에 대처 할 수 있는지 궁금 할 수 있습니다. Hadoop의 2.x 버전에서 업데이트 된 Standby NameNode에 대해서 말씀드리고자 합니다.
2.1 Active Namenode
Active Namenode는 실제로 동작을 수행하는 Namenode입니다.
https://likebnb.tistory.com/162 블로그를 토대로 공부 해 본 결과 다음과
기존의 SecondaryNamenode는 그저 editlogs를 주기적으로 fsimage로 만들어 Namenode에게 전달하는 개념이였습니다. 하지만 Standby Namenode는 실제로 Active Namenode가 문제가 발생해서 정지 될 시 대신 수행 할 수 있는 또 하나의 Namenode로 동작합니다.
그러면 SecondaryNamenode의 동작은 어떻게 될까요?
바로 Standby checkpoint 스레드를 실행합니다. 이 스레드가 하는 일은 SecondaryNamenode와 동일하게 일정 간격마다 fsimage를 교체해주는 일을 수행합니다.
2.2 Standby Namenode
모든 Namenode는 HDFS가 실행되고 나서 모두 Standby Namenode가 됩니다. 그 이후 실행 될 Namenode가 Active Namenode로 전환되어 실행합니다.
Standby Namenode는 Active Namenode의 edit logs 파일을 지속적으로 관찰하면서 변화가 생길 때마다 추적합니다. 뿐만 아니라 Active Namenode로 승격하기 전 반영되지 않은 edit logs가 있는지를 파악하고 완전히 동기화 한 후 전환됩니다.
지속적으로 edit logs를 추적하고 있기 때문에 Standby checkpoint ( Hot-Standby Namenode )에 의해서 fsimage를 업데이트 할 수 있습니다.
Active Namenode와 Standby Namenode는 HTTP 통신을 할 수 있도록 각기 다른 포트를 부여 받습니다. 저는 Docker를 사용했기 때문에 각 docker 별로 원하는 포트를 설정했습니다.
55c875fa4700 wxwmatt/hadoop-namenode:2.1.1-hadoop3.3.1-java8 "/entrypoint.sh /run…" 2 weeks ago Up 7 days (healthy) 0.0.0.0:9000->9000/tcp, 0.0.0.0:9870->9870/tcp namenode
a0cb13bb07c4 wxwmatt/hadoop-datanode:2.1.1-hadoop3.3.1-java8 "/entrypoint.sh /run…" 2 weeks ago Up 7 days (healthy) 0.0.0.0:9864->9864/tcp datanode
ad06bcba1304 wxwmatt/hadoop-resourcemanager:2.1.1-hadoop3.3.1-java8 "/entrypoint.sh /run…" 2 weeks ago Up 7 days (healthy) 0.0.0.0:8088->8088/tcp resourcemanager
9e780b50db37 wxwmatt/hadoop-historyserver:2.1.1-hadoop3.3.1-java8 "/entrypoint.sh /run…" 2 weeks ago Up 7 days (healthy) 0.0.0.0:8188->8188/tcp historyserver
cd914d40ce39 wxwmatt/hadoop-nodemanager:2.1.1-hadoop3.3.1-java8 "/entrypoint.sh /run…" 2 weeks ago Up 7 days (healthy) 0.0.0.0:8042->8042/tcp nodemanager
2.3 Version 3에서는 Active - Standby - observe Namenode
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/ObserverNameNode.html를 참고하면 기존의 Single Point Of Failure 의 방식으로 동작하던 Namenode의 문제점을 지적하고 그에 대해 해답을 제안합니다.
Standby를 이용해서 하나의 Namenode에서 문제가 발생 했을 때의 방안을 제안했지만, 여전히 문제는 남아있었습니다. 그 문제 중 가장 큰 점이 바로 클라이언트의 요청입니다. 어쩌면 서버에서 가장 잘 일어 날 수 있는 문제지만, Active Namenode가 부하로 인해 정지되더라도 Standby Namenode가 그 부하를 모두 처리 할 수 있을지는 의문입니다.
그래서 해답은 Single Point Of Failure 자체에 대한 해결책으로 Observe라는 개념을 제안했습니다. Observe Namenode를 사용함으로써 Namenode로 오는 클라이언트의 요청을 로드밸런싱을 할 수 있게 되었습니다.
3. Scalability ( 확장성 )
“HDFS는 클러스터의 다양한 노드에 데이터를 저장하므로 요구 사항이 증가함에 따라 클러스터는 수백 개의 노드로 확장할 수 있습니다.”
즉 많은 데이터를 저장 할 때 노드를 늘리는 방식으로 해결 할 수 있다는 이야기입니다. 기존의 RDB는 단일 서버의 스펙을 높이는 것으로 문제를 해결 할 수 있었지만, 이 방식은 많은 비용을 초래합니다. 하지만 중간 크기의 디스크를 가진 노드를 늘리면 상대적으로 더 적은 비용으로 확장 할 수 있습니다.
4. High throughput ( 높은 처리량 )
“HDFS는 데이터를 분산 방식으로 저장하기 때문에 노드 클러스터에서 데이터를 병렬 처리할 수 있습니다. 이를 통해 데이터 인접성(다음 글머리 기호 참조)을 추가하여 처리 시간을 단축하고 높은 처리량을 실현할 수 있습니다.”
사실 이 문장은 대용량의 데이터의 처리라는 키워드가 포함되어야 합니다. 데이터를 병렬 처리하는 방법은 대용량의 데이터를 개별적으로 처리(map)하고 결과를 종합하는(reduce)를 할 수 있는 환경을 제시하지만, 네트워크 통신이 필수적입니다. 하지만 대용량의 데이터의 경우에는 좋은 성능을 보입니다.
5. Data locality ( 데이터 지역성 )
“HDFS를 사용하면 데이터가 계산 단위가 있는 곳으로 이동하는 대신 데이터가 있는 데이터 노드에서 계산이 수행됩니다. 이 접근법은 데이터와 컴퓨팅 프로세스 사이의 거리를 최소화함으로써 네트워크 혼잡을 줄이고 시스템의 전체 처리량을 향상시킨다.”
높은 처리량과 비슷한 이야기입니다. 데이터가 있는 노드에서 연산을 수행 할 수 있기 때문에 이 후 Reducing 할 때 네트워크 통신을 최적화 할 수 있습니다.