Fluentd를 사용 한 이벤트 데이터 수집
이 글은 현업에서 Fluentd를 사용하여 이벤트 데이터를 수집 및 DW에 적재하는 과정에서 공부 한 내용을 정리하는 글 입니다.
이벤트 로그 데이터를 수집 한다는 것
Fluentd를 활용하기 전 데이터를 수집하는 것에 대해 이야기를 하면 좋을 것 같습니다.
데이터의 소스는 다양한 곳에서 추출 할 수 있습니다. 웹 상의 데이터를 크롤링하여 얻는 방법, REST API로 제공하고 있는 데이터를 HTTP Request로 얻는 방법 등 다양합니다.
하지만 위의 두 방법은 이미 존재하는 데이터를 수집하는 방법에 속한다면 저는 존재하지 않았지만 현재 발생하는 정보를 얻는 방법에 관해서 이야기 할 예정입니다.
“현재 발생하는 정보”는 다시말해 “연속적으로 발생하는 정보”라고 할 수 있습니다. 데이터를 배치로 처리를 하든 스트림으로 처리를 하든 데이터의 발생 자체가 연속적인 데이터를 처리하게 됩니다.
예를 들면 이러한 로그들과 같은 데이터 입니다.
C 유저가 접속 한 로그
B 유저가 접속 한 로그
B 유저가 A` 제품을 구매 한 로그
A 유저가 접속 한 로그
B 유저가 B` 제품을 구매 한 로그
A 유저가 A` 제품을 구매 한 로그
C 유저가 장바구니에 A` 물건을 등록 한 로그
위 데이터는 시간의 순서대로 (네트워크 등의 문제로 그렇지 않을 수 있지만) 발생하는 이벤트의 로그입니다. 저는 이러한 데이터를 수집하여 배치로 DW에 적재하는 파이프라인을 구축했습니다.
데이터 수집기란
데이터를 수집하는 방법은 여러가지 방안을 사용 할 수 있습니다. GET Request를 받은 Nginx와 같은 웹 서버에서 로그 형태로 수집하여 읽는 방법도 있고, Request 자체를 REST API 서버를 구축하여 데이터를 받을수도 있습니다. 하지만 이렇게 개발하게되면 어떠한 서비스를 확장 할 때 개별적으로 확장해야 합니다.
수집 한 데이터를 ElasticSearch로 적재하려면 그에 맞는 데이터 형식으로 변환해야하고, HDFS 서버로 전송하려면 해당 서버로 전송하여 CopyFromLocal을 수행해야 합니다.
확장을 포함하여 빠르게 개발하기 위해 공통의 로직으로 획일화 하여 만든 프로그램이 Fluentd와 Logstash와 같은 데이터 수집기 입니다.
Fluentd를 사용 한 이유
위에서 저는 2가지의 데이터 수집기에 대해 이야기 했습니다. 그러면 왜 Fluentd를 사용했는지를 설명해야 문맥이 맞을 것이라고 생각합니다.
Logstash
Logstash는 JVM 위에서 동작하는 JRuby로 된 데이터 수집기입니다. ElasticSearch를 만든 Elastic 에서 만들었으며, 그렇기 때문에 ElasticSearch와 매우 호환성이 좋은 수집기입니다.
여기서 호환성이 좋다는 말을 덧붙였는데, 실제로 Fluentd를 사용하면서 Elastic과 관련한 플러그인을 봤는데 데이터의 형식을 맞추기 위한 설정들이 꽤나 많은 걸 볼 수 있었습니다. 그에 비해서 Logstash는 그리 어렵지 않게 ElasticSearch로 데이터를 색인 할 수 있죠.
그런데 JVM위에서 동작하는 점이 조심스럽습니다. 기기나 운영체제에 따른 호환성을 따지면 JVM은 정답에 가깝지만, 하나의 데이터가 하나의 객체로 힙 영역에 쌓이면서 처리 이후 GC의 대상이 된다는 점은 처리량 관점에서 영향이 있을 가능성이 있습니다.
그러면 문제를 제대로 확인해보아야 합니다.
1. 우리는 ElasticSearch를 사용 할 예정인가?
초기에는 사용 할 수 있을 것이라고 생각했지만, 팀원간의 의사소통 이후 사용 가능성이 낮다고 판단했습니다.
2. 우리가 데이터 수집기를 활용 할 서버의 환경이 유동적인가?
이 또한 유동적이지 않습니다. IDC에서 온프레미스 서버로 활용하는 환경은 리눅스 환경으로 고정적이였으며, 특정 플랫폼이나 운영체제를 사용할 예정은 없었습니다.
설령 AWS의 인스턴스를 사용하더라도 리눅스 환경에서 동작 시킬 예정이이였습니다.
그러면 굳이 메모리 사용량과 처리량 측면에서 불리 할 가능성이 있는 Logstash를 사용 할 이유는 없다고 생각했습니다.
Fluentd
Fluentd는 CRuby를 활용하는 데이터 수집기로 C언어 계열이기 때문에 JVM과 같은 부하를 굳이 감수 할 필요가 없습니다. 그리고 오픈소스로 다양한 플러그인을 활용하여 많은 플랫폼과의 상호작용을 기대 할 수 있습니다.
운영체제에 따라 Fluentd의 활용이 어려운 부분은 있지만, 리눅스 환경에서는 대부분 Fluentd의 활용에는 어렵지 않습니다. 결과적으로 일간 약 1억 5천만건의 데이터를 처리하는 수집기를 개발하기위한 적합한 도구라고 판단했습니다.
Fluentd에 대한 내용
Fluentd를 사용하게 되었으니 더 자세한 내용을 포함하고자 합니다.
공식 문서를 확인하면 알 수 있듯, Fluentd는 문서가 정말 깔끔하게 정리되어 있으며 많은 플러그인이 있는 것을 확인 할 수 있습니다.
동작과정을 표현하면 다음과 같습니다.
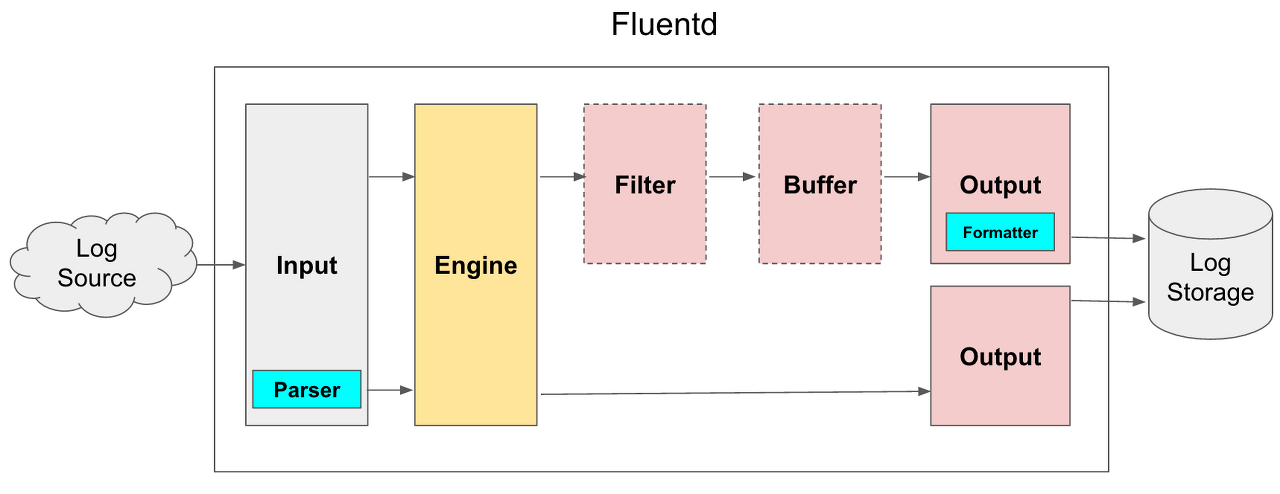
위의 프로세스는 Fluentd의 프로세스 안에서 동작하는 방식입니다. 이제 하나씩 분해하면서 그 과정을 따라가보도록 하겠습니다.
1. Input
Input은 Source 데이터를 가져오는 과정입니다. 여기에는 HTTP Request(POST)의 요청을 받은 서버로의 동작으로 만들 수 있으며, 파일을 tail -f하여 디스크에 쓰여지는 로그를 읽어 낼 수 있습니다.
뿐만 아니라, Kafka나 RabbitMQ와 같은 메시지를 Consume하는 것도 하나의 입력으로 활용 될 수 있습니다.
그리고 중요 한 점은 이렇게 받은 데이터는 Fluentd에서 공통으로 활용하는 형태로 바뀌게 됩니다. 그 형태는 바로 Timestamp와 Tag, Record입니다.
Timestamp
서버가 해당 데이터를 입력받은 시점의 서버 시간입니다. 대부분 문제는 없지만 여기서 중요한 것은 서버 시간이라는 점 입니다.
저는 다국가의 데이터를 다루었기 때문에 서버 시간보다 이벤트의 발생 시간이 중요한 부분이였습니다. 그래서 실제로 이 Timestamp 대신 로그 내 시간을 활용했습니다. 하지만 이러한 Timestamp도 변경 할 수 있는 플러그인이 있기 때문에 그걸 활용하면 됩니다.
Tag
Tag는 데이터가 속해있는 그룹으로 생각하면 됩니다. 이후 로직에서 데이터를 처리하는 과정에서 우리가 어떤 데이터를 처리 할 것인가?의 답을 내는 것이 이 Tag입니다.
예를 들면 유저의 데이터만을 별도로 처리하도록 한다면, Tag의 값을 “user_{group}”과 같이 설정한 뒤에 우리는 user_로 시작하는 데이터를 처리 할 것이다는 속성을 설정하면 됩니다.
Record
이 값은 실제로 입력받은 데이터를 담고있는 속성입니다. 형식으로는 Python의 Dict, Java의 Map이라고 생각하시면 이해하기 편할 것 같습니다. 실제로 Ruby언어로 해당 필드의 값을 바꾸면 그와 비슷하게 동작합니다.
이러한 Record 내의 값을 변경하거나 추가하는 등의 플러그인은 Fluentd에서 공식 플러그인으로 지원하고 있습니다.
2. Parser (Optional) - in Input area
Parser는 Input에서 Record를 지정하는 부분으로 생각하면 편할 것 같습니다. 위에서 Record는 실제로 입력받은 데이터를 저장하고 있는 부분이라고 했지만, 그 데이터가 어떤 것인지 알기 어려 울 수 있습니다.
POST Request의 경우에는 Json 형태로 입력받으면 Record로 변환하기에 편합니다. 이유는 Record 자체가 Json의 형식과 비슷하기 때문이죠. 하지만 Nginx의 access.log는 어떨까요? 이러한 문제가 Parser가 Optional인 이유입니다.
Nginx는 로그의 형식을 자유롭게 지정 할 수 있습니다. 문제는 그 로그의 형식에 따라서 데이터를 파싱해야하는데 어떻게 파싱 할 수 있는가입니다.
여기서 사용하는 것은 정규표현식입니다.
정규 표현식을 사용하여 각 데이터를 부분으로 나누어서 컬럼값을 포함하게 하면 Fluentd는 자동으로 Record 형식으로 변환해줍니다. 뿐만 아니라 Timestamp의 시간도 Nginx의 로그 시간으로 설정하도록 해줍니다.
이 동작은 데이터를 입력받음과 동시에 실행하기 때문에 Parser는 Input 영역에 포함되어 있습니다.
3. Filter (Optional)
Filter는 단어 그대로의 의미인 필터링을 수행하는 과정입니다. 하지만 여기에는 이전의 과정을 통해 얻은 데이터를 변환하는 작업이 포함됩니다.
예를들면 일반적으로 생각하는 Filtering은 다음과 같은 작업을 수행합니다.
Tag가 user_action_*의 형식을 띄고있는 값들만을 남기고 다른 정보는 무시합니다.
우리가 유저의 행동 데이터를 처리하고 싶다면 수집기 단계에서 이렇듯 필터링을 거칩니다. 하지만 Filter 단계에서는 내부의 값을 통해 정보를 변환하는 일종의 Transform을 포함합니다.
Tag가 user_action_*의 형식을 띄고있는 데이터는 Record에 action_group이라는 속성을 추가하고 그 값을 user_action_ 이후에 등장하는 단어로 설정합니다.
저의 경우에는 국가별로 시간대가 다르기 때문에 실제로 데이터를 저장 할 떄 그 값이 다양한 시간대로 저장되는 문제가 있었기 때문에 그 값을 변환하는 작업을 수행했었습니다. 뿐만아니라 입력 된 시간을 기준으로 악의적으로 시간대를 바꾼 유저들의 데이터를 무시하는 등의 작업또한 추가했었습니다.
Log에 포함 된 유저의 기기 기준의 시간을 Ruby 자체의 date관련 라이브러리를 활용해서 PST 시간으로 변환합니다.
변환 된 시간을 기준으로 현재 시점보다 N일 전, 혹은 그 이후라면 제거합니다.
이렇게 작업할 수 있습니다. 실제로 할 수 있는 작업이 훨씬 많기 때문에 이 부분은 직접 확인하시면 넓게 활용하실 수 있을 것이라고 생각합니다.
4. Buffer ( Optional ) - in Output area
버퍼는 위의 과정이 모두 실행 된 형태의 데이터를 임시로 쌓아놓는 과정입니다. 이 과정이 필요한 이유는 배치에 대한 이유가 있으면 쉽게 이해하실 수 있을 것이라고 생각합니다.
Buffer는 크게 두 가지의 방식으로 데이터를 저장하고 그 데이터들을 설정 한 시간에 맞추어 Flush하는 방식으로 동작합니다. 두 가지의 방식이란 메모리에 적재하는 방식과 디스크에 저장하는 방식입니다.
알다시피 메모리는 상대적으로 적은 용량을 가지고 있습니다. 하지만 처리속도는 디스크에 비교해서 매우 빠르기 때문에 실시간( 주로 마이크로 배치 )으로 처리되는 작업의 경우에는 필수적으로 메모리를 활용해야 합니다.
하지만 저의 경우에는 1시간 단위의 매 정각에 실행하는 배치처리를 개발했었기 때문에 버퍼는 1시간동안 처리 된 데이터를 저장했습니다. 이 경우에는 1회 처리 후 다음 처리가 1시간 후라는 점이 명확하기 때문에 처리 시간에 대해서는 부하가 크지 않지만, 쌓이는 데이터는 많습니다.
이 경우 디스크를 사용하는 것이 옳은 선택입니다. Fluentd에서는 이러한 동작을 할 때 발생할 수 있는 문제점에 대해서 해결하고자 노력 한 점이 보입니다.
예를 들면 “만약 갑자기 빠른 데이터 입력으로 이전의 과정을 거치는 데이터가 도달하지 못한게 아닐까?”라는 문제에 대해서 Fluentd는 “그러면 Flush하는 것을 정각에서 N분 늦춰서 처리를 대기해줄게”라는 방식으로 유연한 대처를 해줍니다.
그 외에도 제가 한 번 당했던 “Flush 속도가 Input 속도를 따라가지 못해서 Buffer가 가득차면 어떻게 할까?” 라는 문제는 Buffer Overflow에 대해서 데이터를 받을지 말지를 결정하는 Block 혹은 에러를 출력하는 등의 처리 방식또한 지원해줍니다.
공식문서는 매우 읽기 쉽게 되어있어서 빠르게 확인하실 수 있습니다. 하지만 특정 설정을 사용하면 Flush 방식이 메모리로 변경되버리는 문제가 있는데, 이 부분은 잘 확인 할 필요가 있습니다.
5. Output
실제로 데이터를 어디로 보낼 것 인지에 대한 정보입니다. ElasticSearch, WebHDFS, File, Forward, stdout 등의 다양한 Output destination이 존재하고, 이 부분은 활용하고자 하는 파이프라인에 맞게 개발하면 됩니다. 제가 이해하기로는 GCS나 S3등의 클라우드 기반의 오브젝트 스토리지 또한 이러한 플러그인이 잘 되어 있습니다.
다양한 플러그인 중 가장 자주 활용 할 것이라고 생각되는 Forward와 stdout에 대해서는 한번 짚어보고자 합니다. 제가 자주 활용한다고 자신있게 말하는 이유는 바로 병렬처리와 테스트에 관련있는 부분이기 때문입니다.
먼저 forward에 대해서 알아보겠습니다.
Forward
Output plugin으로 forward를 사용하면 우리는 버퍼에 쌓여있는 데이터를 다른 fluentd로 전송합니다. 이 말 뜻은 결국 로드 밸런싱이 가능하다는 의미입니다.
제가 처음 Fluentd를 사용하여 파이프라인을 만들었을 때 Input과 Filter, Output까지 모두 하나의 프로세스에서 동작하도록 개발을 했었습니다. 그 당시에는 활용가능성을 알아보기 위한 프로토타입이였지만, 그럼에도 그 처리 속도는 초당 약 2000개의 로그를 처리하는 정도였습니다. 그 당시 테스트 데이터는 모든 로그가 이미 쌓여있는 하나의 파일을 읽는 방식이였기 때문에 동시에 쓰여지는 로그의 경우 약간 적어질 수 있죠.
하지만 프로젝트를 시작했을 때 저는 지금보다 더 많은 데이터를 처리 할 것이라는 예정을 들었습니다. 그 양은 현재의 약 1.5배 정도로, 처리량을 더 높일 필요성을 느꼈습니다.
그렇게 Fluentd의 성능의 향상을 위해 알아 본 결과 각 과정을 병렬로 처리하면 그 결과를 얻을 수 있음을 알았습니다. 바로 forward Output을 활용하는 방법이죠.
하나의 프로세스에서 Input과 Output의 파이프라인을 설정합니다. 여기서 Input은 Source에서 데이터를 읽어오는 방식이고 Output은 forward로 데이터를 다른 서버들로 전송하는 방식입니다. forward Output Plugin의 설정에서 로드밸런싱으로의 활용을 적극 지원하기 때문에, 서버의 상태에 따라 얼마동안의 health check 시간을 가질 것인지, 얼마의 비율로 데이터를 전송 할 것인지를 설정 할 수 있습니다.
당연히 이 때의 buffer는 Memory입니다. 실시간에 가깝게 데이터를 각 서버로 전송하고, 여유롭게 thread를 설정해야 네트워크 IO가 빈번한 상황에서의 처리량을 확보 할 수 있습니다.
그리고 다른 프로세스들에서 이 값을 Input으로 받아서 활용합니다. Filter와 실제 Output이 여기에 속할 것 같습니다.
이렇게 프로세스를 개선 했을 때 실제로 처리량이 약 5배 가량 높아진 것을 확인했습니다. 20개의 CPU를 사용중인 서버에서 1개의 Source Input 프로세스, 4개의 Service 프로세스를 구성했으니 적절하게 예상 한 성능만큼 확보 했음을 알 수 있었습니다.
stdout
주로 문제가 발생하거나, 그 과정을 살펴볼 때 저희는 로그를 읽습니다. File로 Output을 떨어뜨리는 것 보다 프로세스의 stdout으로 떨어뜨리는게 문제의 원인을 파악하기에 더 효과적이였습니다.
Fluentd에서는 Output의 대상에 대한 복제도 지원함으로써 동시에 여러가지의 Output을 제공하기 때문에 초기 개발 단계에서 stdout을 별도로 구성하는 것은 그리 나쁜 선택은 아닐 것 같습니다. 물론 정식 서비스에서는 서버에 부하가 될 수 있으니 주의해야합니다.
WebHDFS
이 부분은 실제로 HDFS를 사용하는 사용자에게 좋은 내용이겠지만, 제가 사용했으며 또 기여하고자 하는 플러그인이기 때문에 내용을 추가했습니다.
저는 작업 환경이 Impala on HDFS였기 때문에 처리 된 데이터가 HDFS에 적재 되어야 했습니다. 즉, 파일 형태로 해당 스토리지 내의 Impala 파티션에 맞추어 데이터가 적재 되어야 합니다. 기존의 HDFS 사용은 CopyFromLocal만 사용하던 저는 이 플러그인을 기점으로 WebHDFS라는 새로운 기능을 활용 할 수 있게 되었습니다.
HTTP 통신을 통해 데이터를 전달하는 방식인 WebHDFS플러그인은 굳이 파일로 만들 필요없이 해당 데이터를 바로 HDFS에 적재 할 수 있도록 해줍니다.
Active Namenode 뿐만 아니라 Standby Namenode를 설정 할 수 있습니다. 이 과정에서 여러 개의 Standby Namenode를 사용 할 수 있도록 MR을 요청했지만, 언제 받아들여질지는 모르겠습니다.
주의 할 점은 네트워크 통신이기 때문에 다양한 경로를 각자의 Buffer로 설정해서 각자 적재 할 수 있지만, 그만큼 작은 파일이 자주 네트워크 IO를 발생시킨다는 점이 있습니다. 배치 단위는 상관없지만, 저는 수 초 단위의 적재를 테스트하다가 Buffer Overflow를 맞았습니다.
주의합시다.
Fluentd를 사용하면서 생각 한 점
Fluentd는 제가 사용한 여러 플랫폼 중에서도 손에 꼽을 정도로 완벽한 Document를 가지고 있습니다. 때문에 사용하는 과정에서 어려움은 없을 것이라고 생각합니다.
하지만 Plugin의 리스트가 공식 문서에는 전부 공개되어 있지 않습니다. 대부분 자주 활용되는 Plugin만이 적혀있기 때문에 별도의 페이지에서 참고하는 것이 도움이 될 것 같습니다.
https://www.fluentd.org/plugins/all
위 페이지에는 현재 사용 가능한 모든 플러그인이 포함되어 있습니다.