Flink의 기본 지식
최근에 프로젝트 진행 중 Flink 를 사용한 데이터 파이프라인을 개발하게 되면서 공부 한 내용을 정리하기 위해 포스트를 작성합니다. 실시간 파이프라인 개발을 담당하게 되면서 기술 스택 중 Flink를 선택하게 된 이유는 “실시간/배치 파이프라인을 지원하면서 Exactly Once를 보장”하는 특징입니다.
Exactly Once에 관련한 내용 및 실시간 파이프라인을 통한 아키텍처 관련 지식은 빅데이터 아키텍처 관련 포스트를 참고하시면 좋을 것 같습니다.
Flink 란
Flink 설계에 대한 기본적인 지식을 얻는 것은 공식 문서를 참조하는 것이 좋습니다. 공식 문서에서는 우리가 Flink에 대해 어떤 지식을 습득해야 하는지를 목차로 친절히 알려주고 있습니다.
- 스트리밍 데이터 처리 파이프라인 구현 방법
- 연속 스트림에서 이벤트 기반 애플리케이션을 구축하는 방법
- 이벤트 시간을 사용해 정확한 분석 결과를 일관되게 계산하는 방법
- Flink가 상태를 관리하는 이유와 방법
- 정확히 한 번 처리(exactly-once semantics)를 보장하는 내결함성 있는 상태 기반 스트림 처리 방식
위 내용에 대해서 기본적인 내용을 포함하여 각 부분에 더 상세한 부분은 별도 문서를 참조하여 설명하거나 별도의 포스트로 정리하도록 하겠습니다.
연속 스트림에서 이벤트 기반 애플리케이션을 구축하는 방법
데이터 유형
Flink의 스트리밍 데이터 처리 파이프라인을 이해하기 위해서는 먼저 Unbounded 데이터와 Bounded 데이터에 대한 이해가 있어야 합니다. Flink에서는 이 두 가지 방식으로 데이터를 이해하고 있으며, 각각 필요에 따라 활용됩니다.
1. Unbounded
무한으로 생성되는 데이터를 말합니다. 예를 들면 사용자 이벤트 로그를 기반으로 특정 정보를 얻는다면, 로그는 언제든지 사용자에 의해 무한으로 생성 될 가능성이 있습니다. 이러한 데이터를 Unbounded 데이터라고 합니다.
2. Bounded
끝이 있는, 어디까지 생성되었는지가 명확한 데이터를 말합니다. 예를 들면 파일을 읽거나 특정 범위의 데이터를 읽는다면 우리는 해당 데이터가 어디에서 시작해서 어디까지 읽어야 하는지를 알 수 있습니다. 보통 이런 경우에는 일반적으로 Unbounded 데이터보다 연산 수와 복잡도가 줄어들기에 더 빠른 연산이 가능합니다.
하지만 Flink를 공부 할 때 주의 할 점은 일반적인 배치 데이터 파이프라인과 Bounded 데이터가 동일 한 개념이 아닐 수 있습니다. 무한히 늘어나는 데이터 속에서 Bounded 데이터를 임의로 만들 수 있기 때문입니다. 공식 문서에서의 그림을 포함하는게 이해가 빠를 것 같습니다.
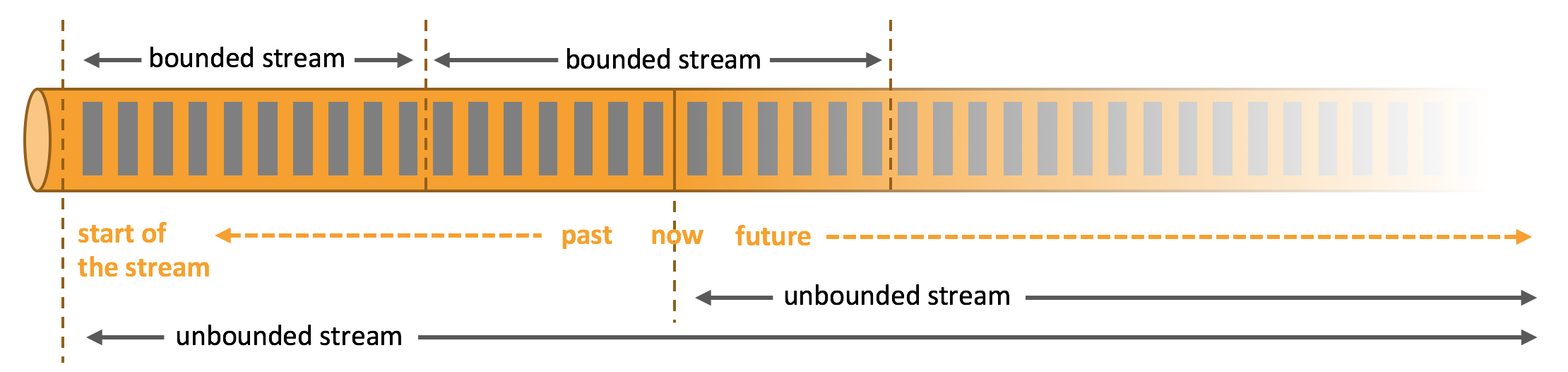
Flink 에서 말하는 배치 파이프라인은 이렇듯 무한히 생성되는 데이터 속에서 일정한 조건을 통해 경계를 구분하여 데이터를 처리하는 것을 의미 할 수 있습니다 (혹은 파일등의 고정 데이터에 대한 배치데이터 일 수 있습니다). 여기서 사용하는 조건은 여러 기준 및 방식이 있으며, 이 포스트에서 “윈도우”에 대한 내용에 포함되어 있습니다.
스트리밍 데이터 처리 파이프라인 구현 방법
Flink 에서는 위의 (Un)bounded 데이터를 처리하기위해 Operator를 구현해야 합니다. 데이터를 얻어오는 Source Operator와 처리를 위한 Transformation Operator 그리고 데이터를 내보내기 위한 Sink Operator 가 그러한 Operator입니다.

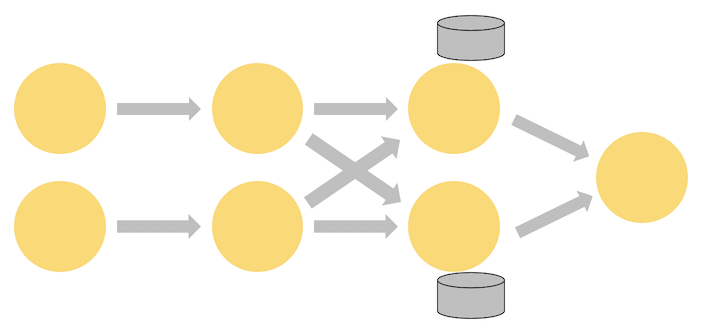
Source Operator, Sink Operator 는 여러 개 존재 할 수 있으며, 마찬가지로 하나의 Transformation도 여러개의 Operator로 구현 될 수 있습니다. 이러한 Operator들은 위 이미지처럼 단방향 그래프(DAG)로 그려지고 순차적으로 작업이 실행됩니다.
이러한 단방향 그래프를 시각화 하면 여러 형태의 그림이 그려질 수 있습니다. 하나의 Operator에서 여러 Sink Operator를 가질 수 있고, 여러 Operator에서 하나의 Sink Operator를 가지거나 혹은 Transformation Operator 사이에서 분산 될 수 도 있습니다.
그리고 각 Operator는 실제 동작에서는 sub task로 나누어집니다. Operator가 동작을 설명하는 하나의 기능에 대한 이론적인 기능이라면 sub task는 실제로 그 기능을 실행하기 위한 구분이며, 실제로 각 sub task는 개별적으로 동작합니다. 이 부분은 이해를 돕기 위해 공식 문서의 그림을 가져와보겠습니다.

그림에서 보면 하나의 Operator는 1개 이상의 sub task로 나누어지고 Stream은 1개 이상의 Stream Partition으로 이루어져 있습니다. 그리고 하나의 Operator가 N개의 sub task로 이루어져 있다면 N Parallelism 이라고 말 할 수 있습니다.
두 Operator 사이에는 두 가지 방식의 Stream이 이루어 질 수 있습니다. One-to-One 또는 Redistributing으로 이 두 방식의 차이는 MapReduce의 shuffling 을 생각하면 이해하기 좋을 것 같습니다.
One-to-One
One-to-One은 두 sub task 사이가 1:1로 연결 된 형태를 말합니다. 이러한 파이프라인의 대표는 shell의 pipe가 있을 것 같습니다.
tail -f log.txt | grep "success" | cut -d ',' -f 1
위의 shell script는 다음과 같은 동작을 수행합니다.
- log.txt 파일을 읽습니다.
- success 단어가 있는 문장을 추출합니다.
- 문장을 , 단위로 잘라서 1번째 문장을 출력합니다.
그리고 이 동작은 동시에 동작합니다. 즉, 1번 동작이 끝나고 2번 동작을 수행하는 것이 아닌 1번과 2번, 3번 동작이 동시에 동작합니다. 즉 이 동작은 스트리밍 파이프라인이라고 말할 수 있으며 동시에 One-to-One 방식으로 동작하는 서비스입니다.
1번 동작이 2번 동작의 여러 sub task에 분산되지 않고, 단 하나의 task에 1번 동작으로 통해 나온 결과를 전달합니다. 그리고 이러한 동작을 하는 이유는 2번 동작(가능여부, 효율 등)이 1번 동작의 결과와 상관없기 때문입니다.
Redistributing
하나의 sub task에서 동일한 Operator의 여러 sub task로 연결되는 것은 곧 병렬 처리를 수행하는 것 입니다. 하지만 모든 Operator에서 이러한 처리를 하는게 아닌 특정 Operator에서 이러한 동작을 수행합니다.
다음의 Operator들이 병렬처리를 수행합니다.
- keyBy (키 기준)
- window (윈도우 기준)
- broadcast (전체 전달)
- rebalance (무작위)
- 등 파티션을 분할 할 조건이 담긴 동작
예를 들면 입력 된 json 데이터에 key 컬럼이 [A,B,A,B,C,D] 와 같이 데이터가 입력되었을 때 해당 키를 기반으로 파티셔닝을 하게 되면 전송 sub task(전달하는 쪽)에서 N개의 수신 sub task(수신 받는 쪽)으로 여러개로 나뉘어져 파티셔닝이 진행되게 됩니다.
이벤트 시간을 사용해 정확한 분석 결과를 일관되게 계산하는 방법
실시간 데이터 파이프라인에서는 실시간으로 처리되는 동일한 로직을 재처리 과정에서도 동일하게 수행되어야 합니다. 이 부분의 안정성을 보장하기 위해서 이러한 문제를 해결하려면 데이터를 언제 처리했는지가 아닌 실제로 데이터가 생성된 시간이 중요합니다.
이러한 문제를 해결하기 위해서는 Flink에서는 메시지 내에 있는 이벤트 타임을 사용하여 어디까지 실행되었는지에 대해서 판단 할 수 있는 방법을 제공하고 있습니다.
Flink가 상태를 관리하는 이유와 방법
Flink 에서는 Operator에 상태가 있을 수 있습니다. 이러한 상태가 있는 이유는 하나의 이벤트에 대한 처리가 이전에 처리 된 모든 데이터의 누적에 따라 달라질 수 있음을 의미합니다. 1분간 처리 된 데이터의 수를 파악하거나 사기 탐지 등의 동작을 수행 할 때 이러한 상태가 주로 사용됩니다.
Flink는 기본적으로 병렬 처리를 수행하며, 하나의 연산자의 여러 서브 인스턴스는 개별의 스레드로 동작하면서 서로 다른 머신에서 동작 할 수 있습니다. 여기서 개별 서브 인스턴스는 샤딩 된 키-값 형식으로 생각 될 수 있습니다. 예를들면 “A 이벤트는 A’ 개별 클러스터로 B 이벤트는 B’ 개별 클러스터로 처리된다”와 같은 방식으로 실행 될 수 있습니다.
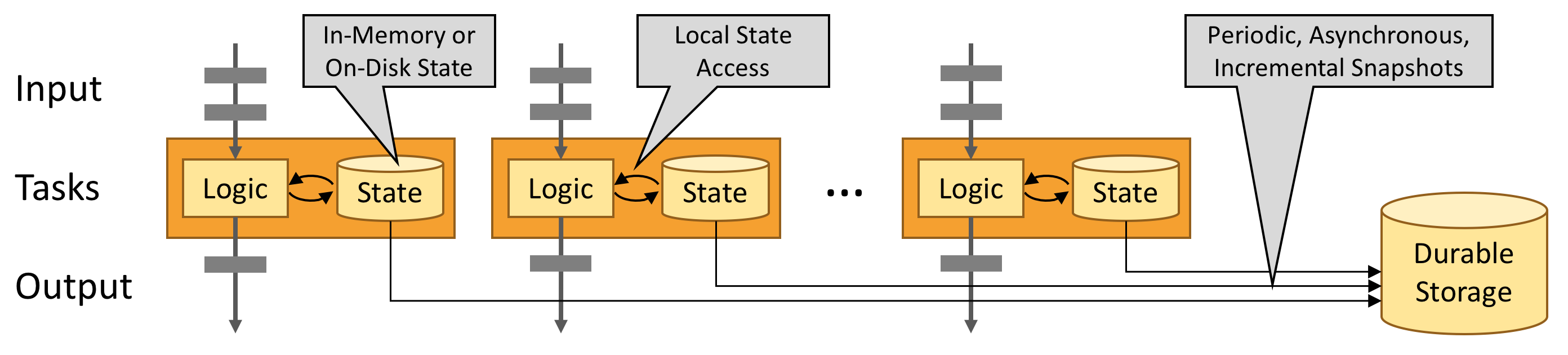
이러한 상태는 기본적으로는 로컬에서 접근하기에 높은 처리량과 낮은 지연율로 사용 할 수 있습니다. 효율을 높이기 위해서는 JVM 힙을 사용 할 수 있고, 크기가 큰 경유에는 효율적으로 구성 된 온디스크 데이터 구조에 저장 할 수 있습니다.
정확히 한 번 처리(exactly-once semantics)를 보장하는 내결함성 있는 상태 기반 스트림 처리 방식
Flink 에서는 상태를 스냅샷하는 방식과 스트림 처리를 활용하여 정확히 한 번 처리하는 로직을 보장합니다. 이 스냅샷에는 분산 처리 파이프라인의 전반적인 상태를 저장되면서, 입력 큐, 오프셋, 시점까지 저장하여 작업 그래프 전반을 저장되어 있습니다. 만약 장애가 발생하면 마지막에 저장 된 상태를 기반으로 복원합니다.
이 내용을 기반으로 이후 Flink를 실제로 사용하면서 얻는 지식을 정리하고자 합니다.