Flink의 Table API 사용 중 조인 및 종합 연산 활용 시 주의 점
최근에 프로젝트 진행 중 Flink 를 사용한 데이터 파이프라인을 개발하게 되면서 공부 한 내용을 정리하기 위해 포스트를 작성합니다.
Flink 란
Flink 설계에 대한 기본적인 지식을 얻는 것은 공식 문서를 참조하는 것이 좋습니다. 공식 문서에서는 우리가 Flink에 대해 어떤 지식을 습득해야 하는지를 목차로 친절히 알려주고 있습니다.
- 스트리밍 데이터 처리 파이프라인 구현 방법
- 연속 스트림에서 이벤트 기반 애플리케이션을 구축하는 방법
- 이벤트 시간을 사용해 정확한 분석 결과를 일관되게 계산하는 방법
- Flink가 상태를 관리하는 이유와 방법
- 정확히 한 번 처리(exactly-once semantics)를 보장하는 내결함성 있는 상태 기반 스트림 처리 방식
이 포스트에서는 위의 목차 중 Flink의 연속 스트림 내에서 애플리케이션을 개발 중 발생하는 문제점에 대해서 공유드리겠습니다.
Flink의 데이터 유형에 관련 한 포스트는 이전 포스트를 참고해주시면 감사드리겠습니다.
Flink의 Table API 사용 시 테이블 종류와 상태에 대해 주의가 필요
Flink에서 Table API를 사용하면 자칫 일반적으로 사용하는 배치 파이프라인에서의 데이터프레임을 생각하기 쉽습니다. 이러한 이유는 데이터프레임과 비슷한 형태로 떨어지는 SQL로 데이터가 표현되기 때문입니다.
일반적으로 SQL로 쿼리하면 전체 데이터가 고정된 스키마애 고정 된 크기로 결과가 떨어지고 CRUD가 적절하게 작동하는 것 처럼 보입니다. 하지만 Flink에서 Table API와 SQL은 그와 동일하게 생각하면 안됩니다.
예를 들면 다음의 문제가 있었습니다.
Table API 사용 시 종합 연산 중 경험 한 문제
문제는 Iceberg에서 데이터를 조회하여 Flink 내에서 조인을 하려는 과정에서 발생했습니다. 정확히는 두 데이터의 조인 후 종합(AGG)연산 과정에서 발생했습니다. 해당 연산은 ARRAY_AGG로 Group By의 조건에 맞는 값들 중 특정 값들을 리스트로 모아서 종합하는 연산입니다.
예를 들면 다음의 예시가 있을 수 있습니다.
df_a (인물 정보)
person_id person_name
0 1 인물1
1 2 인물2
2 3 인물3
3 4 인물4
4 5 인물5
5 6 인물6
6 7 인물7
7 8 인물8
8 9 인물9
9 10 인물10
10 11 인물11
11 12 인물12
12 13 인물13
13 14 인물14
14 15 인물15
15 16 인물16
16 17 인물17
17 18 인물18
18 19 인물19
19 20 인물20
20 21 인물21
21 22 인물22
22 23 인물23
23 24 인물24
24 25 인물25
25 26 인물26
26 27 인물27
27 28 인물28
28 29 인물29
----
df_b (출연 정보)
program_name person_id
0 전지적 참견 시점 1
1 무한도전 1
2 런닝맨 1
3 무한도전 2
4 유 퀴즈 온 더 블럭 3
5 라디오스타 4
6 놀면 뭐하니 4
7 무한도전 5
8 전지적 참견 시점 6
9 유 퀴즈 온 더 블럭 7
10 1박 2일 7
11 무한도전 7
12 유 퀴즈 온 더 블럭 8
13 라디오스타 9
14 무한도전 9
15 전지적 참견 시점 10
16 유 퀴즈 온 더 블럭 10
17 놀면 뭐하니 10
18 전지적 참견 시점 11
19 무한도전 12
20 라디오스타 13
21 놀면 뭐하니 13
22 1박 2일 14
23 전지적 참견 시점 15
24 1박 2일 15
25 나 혼자 산다 16
26 유 퀴즈 온 더 블럭 17
27 놀면 뭐하니 17
28 무한도전 17
29 놀면 뭐하니 18
30 무한도전 19
31 전지적 참견 시점 19
32 1박 2일 19
33 놀면 뭐하니 20
34 1박 2일 20
35 전지적 참견 시점 21
36 놀면 뭐하니 22
37 라디오스타 23
38 무한도전 24
39 놀면 뭐하니 24
40 라디오스타 25
41 무한도전 25
42 유 퀴즈 온 더 블럭 26
43 나 혼자 산다 26
44 전지적 참견 시점 27
45 라디오스타 27
46 놀면 뭐하니 27
47 런닝맨 28
48 나 혼자 산다 29
49 놀면 뭐하니 29
50 라디오스타 29
위와 같은 데이터가 있을 때 조인하고 종합 연산으로 ARRAY_AGG 연산을 할 경우 다음의 결과를 기대합니다.
df_c 실 출연 정보
0 1박 2일 [인물7, 인물14, 인물15, 인물19, 인물20]
1 나 혼자 산다 [인물16, 인물26, 인물29]
2 놀면 뭐하니 [인물4, 인물10, 인물13, 인물17, 인물18, 인물20, 인물22, 인물24...
3 라디오스타 [인물4, 인물9, 인물13, 인물23, 인물25, 인물27, 인물29]
4 런닝맨 [인물1, 인물28]
5 무한도전 [인물1, 인물2, 인물5, 인물7, 인물9, 인물12, 인물17, 인물19, 인물...
6 유 퀴즈 온 더 블럭 [인물3, 인물7, 인물8, 인물10, 인물17, 인물26]
7 전지적 참견 시점 [인물1, 인물6, 인물10, 인물11, 인물15, 인물19, 인물21, 인물27]
하지만 Flink의 StreamMode에서 Table API로 데이터를 불러 온 뒤 조인을 하고 그 결과를 카프카 토픽으로 전송했을 때 다음과 같은 결과가 전달되었습니다.
program_name person_name_list
0 1박 2일 [인물7, 인물14]
1 1박 2일 [인물7, 인물14, 인물15]
2 1박 2일 [인물7, 인물14, 인물15, 인물19]
3 1박 2일 [인물7, 인물14, 인물15, 인물19, 인물20]
4 나 혼자 산다 [인물16]
5 나 혼자 산다 [인물16, 인물26]
6 나 혼자 산다 [인물16, 인물26, 인물29]
7 놀면 뭐하니 [인물4]
7 놀면 뭐하니 [인물4, 인물9]
...
일반적으로 배치 파이프라인에 익숙한 데이터 엔지니어는 이러한 상태에 대해서 이해하기 어려운 상황입니다. 스트림 파이프라인을 개발하는 엔지니어도 일정량의 스트림을 모아서 조인(종합)하여 처리하는 경우 이런 문제를 경험하기 어려울 수 있습니다.
문제에 대한 고찰
위의 사례가 왜 발생했는지에 대한 고찰이 필요합니다. 우리가 생각하는 일반적인 데이터프레임 형태라면 위와 같은 결과는 절대 발생하지 않습니다. 그 이유는 보통의 경우 df_a와 df_b는 고정 된 크기의 데이터이고, 두 데이터를 조인하는 경우인 df_c는 마찬가지로 고정 된 크기의 연산에 맞는 결과를 보여야합니다.
그런데 위 결과는 몇 가지 이상한 점이 보입니다.
마치 person_name_list가 증분되어 합쳐져 보이는 점 입니다. 그리고 그러한 결과가 나오기 위해서는 과거 상태가 저장되어 보입니다.
원인을 파악하기 위한 과정
이 문제를 자세히 알아보기 위해서는 몇 가지 개념을 이해 할 필요가 있습니다.
- Streaming Mode와 Batch 모드에서 Table API의 SQL을 사용하면 어떤 형식으로 동작하는가
- 동적 테이블이란
- 동적 테이블의 연산 과정
- SQL로 데이터를 조인, 종합 등의 연산을 하면 어떤 일이 발생하는가
- Table API에서 상태는 어떻게 관리되는가
- 발생한 문제에 대한 원인
- 각 과정에 대한 설명
위 내용을 순차적으로 알아보도록 하겠습니다. 모든 정보는 모두 Flink 공식 웹 사이트를 참조했습니다.
Streaming Mode와 Batch 모드에서 Table API의 SQL을 사용하면 어떤 형식으로 동작하는가
일단 Table API와 SQL의 사용에 대해서는 Unbound 데이터나 Bound 데이터 여부와 상관없이 스트리밍 처리 방식으로 처리 됩니다. 즉 우리가 Table API로 배치 파이프라인을 개발하더라도 내부적으로 스트리밍으로 처리됩니다.
즉, 위에서 df_a와 df_b를 조인하는 형태는 Bound 데이터와 Bound 데이터를 조인하는 일반적인 데이터 파이프라인이 아니라는 점을 직관적으로 알 수 있습니다. 그러면 df_a와 df_b는 어떤 형태를 가진 테이블인지 알아봐야 합니다. 일반적으로 데이터를 읽을 때 특별한 DML 없이는 변경되지 않는 정적인 테이블로 읽어오는데, 두 데이터는 다른 형태로 보여집니다.
Table API&SQL을 사용하더라도 Flink는 스트리밍 처리를 지원해야하기 때문에 정적 테이블이 아닌 동적 테이블로 데이터를 만듭니다. Flink 공식 문서에는 이러한 데이터를 RDB의 Materized View와 유사하다고 말합니다.
다음은 RDB의 테이블의 형태와 Flink의 테이블 형태를 비교 한 표입니다.
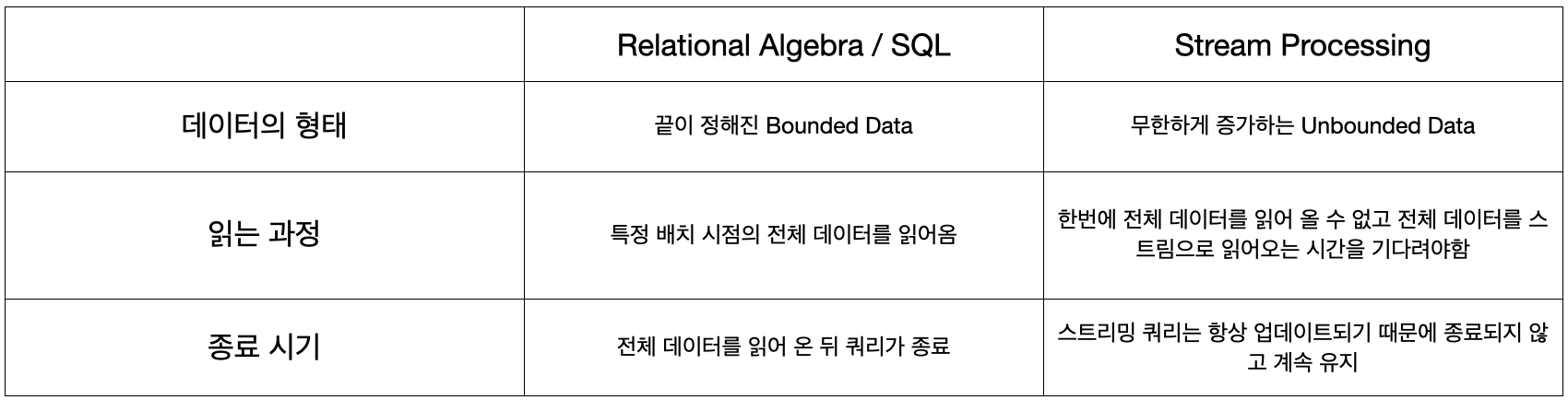
위 표에서 보면 스트림 데이터는 항상 업데이트되어야 하며 쿼리가 종료되지 않고 계속 실행중이라는 점을 볼 수 있습니다. 우리가 이러한 형태를 계속 유지하기 위해서 동적 테이블이라는 개념을 사용해야합니다.
동적 테이블이란
동적 테이블은 Flink에서 Table API 혹은 SQL로 스트리밍 서비스를 유지하기 위해서 사용하는 테이블입니다.
동적 테이블은 RDB와 같이 한 번 쿼리하면 일회성으로 얻어오는 정적인 테이블이 아닌 연속적인 쿼리를 지속적으로 업데이트되어지는 동적인 테이블입니다. 예를들면, 지속적으로 입력되는 임의의 스트림 데이터가 있을 경우 정적 테이블은 특정 시점 기준의 전체 데이터를 읽어오고 해당 데이터가 이후 쿼리에서 사용됨이 보장 됩니다. 하지만 동적 테이블을 사용하면 지속적으로 변경되는 사항이 반영된 데이터를 실시간으로 읽어 올 수 있게 됩니다.
그러면 이러한 걱정을 할 수 있습니다.
“테이블이 모두 메모리에 올라 간 상태가 아닌가?”
Flink에서는 이러한 테이블에 올라간 데이터를 얼마나 유지 할 것인지에 대한 TTL을 지원합니다.
동적 테이블의 연산 과정
동적 테이블은 말 그대로 동적으로 업데이트되는 테이블이기 때문에 각 이벤트가 입력되는 시점마다 변경되게 됩니다. 그리고 Flink는 완전 실시간을 지원하기 위해 각 레코드 단위의 연산을 지원하고 있습니다. 즉, 동적 테이블을 사용해서 카프카 등의 데이터 원천에서 데이터를 소싱하게 되면 매우 짧은 가격(약 ms,ns에 가까운 간격)으로 테이블이 지속적으로 업데이트 되어지면서 스트림을 따라 가장 최신 데이터를 추적합니다.
Flink 공식문서에서도 제가 발생시켰던 문제와 유사한 예시를 첨부해놓았습니다.
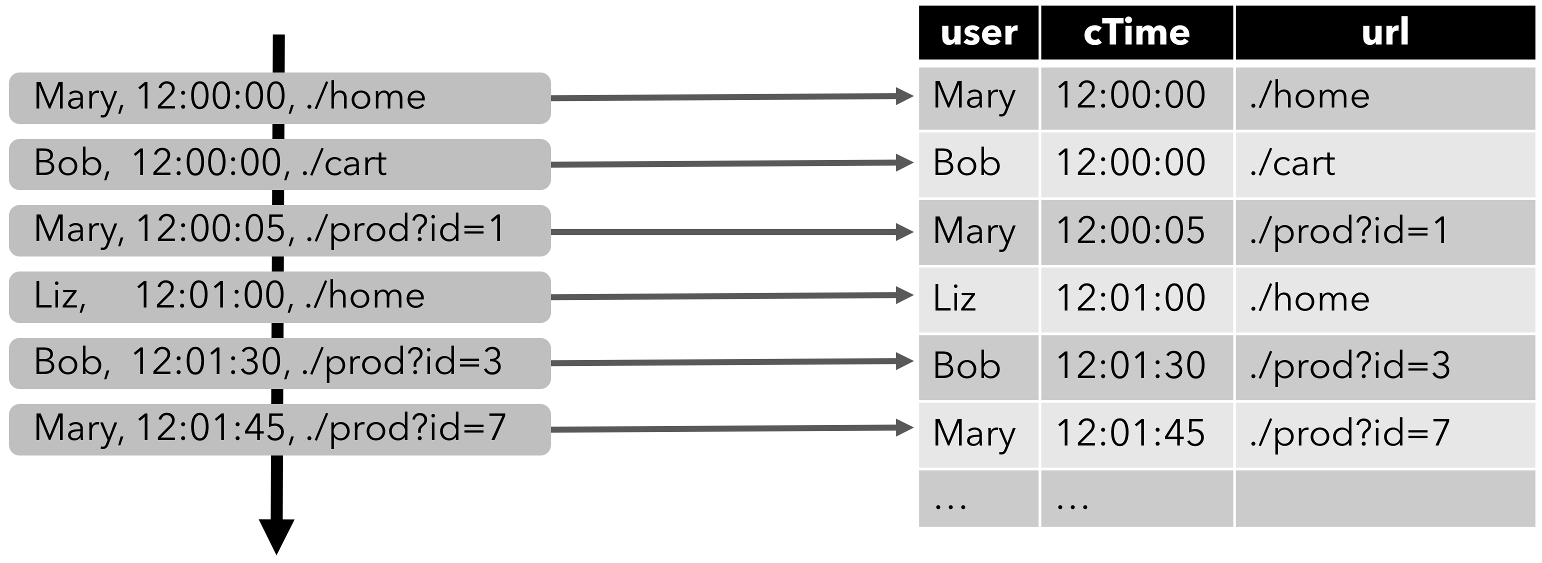
위와 같은 데이터 셋이 연속적으로 입력되는 경우, 만약 이름을 기반으로 유저의 클릭수를 얻기위한 종합 연산을 사용하면 다음과 같은 동작이 수행됩니다.
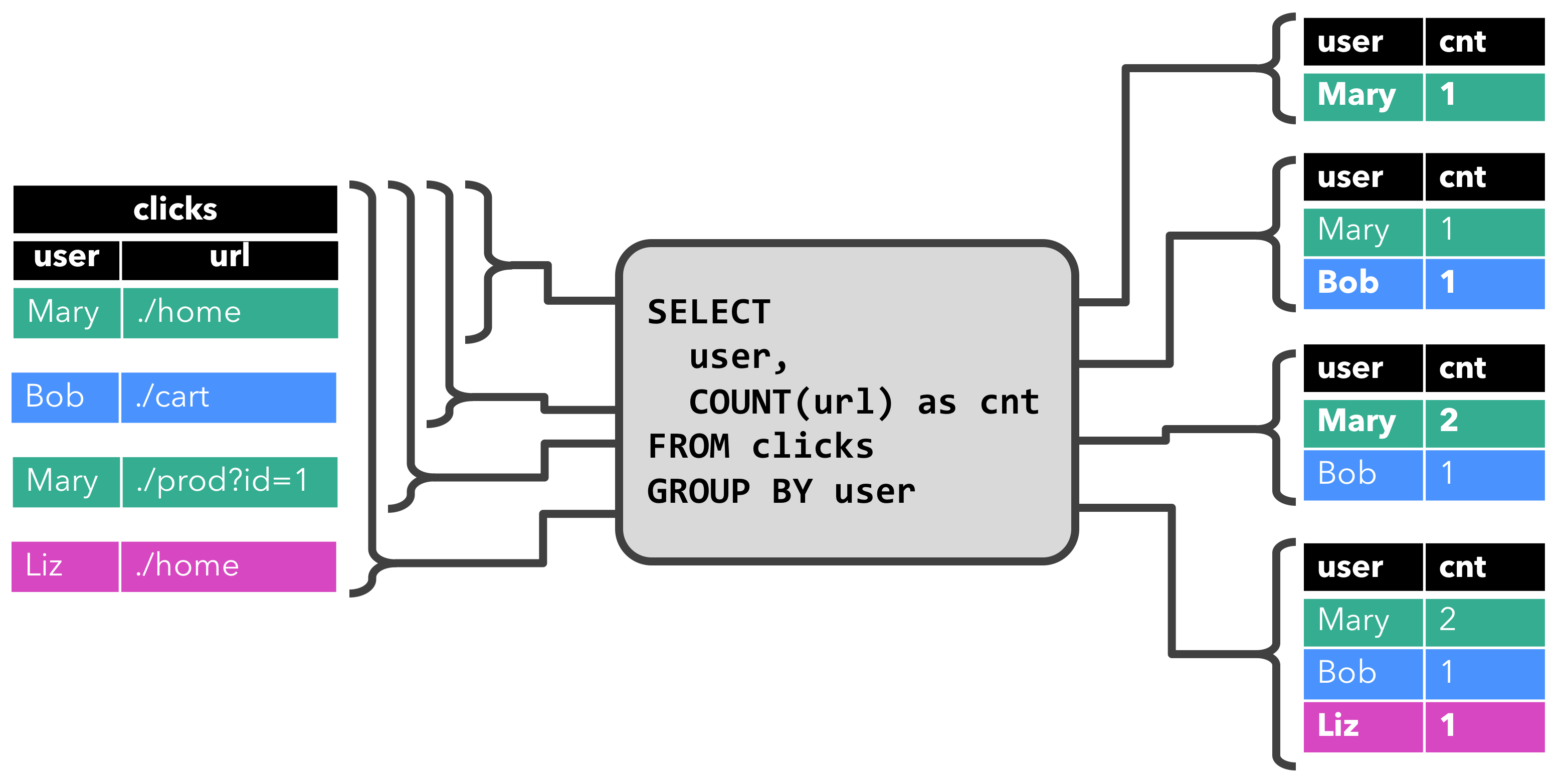
이러한 결과는 Continuous Queries를 사용하는 경우 자연스럽게 발생하는 문제입니다. 이제 우리는 왜 이런 문제가 발생했는지에 대해서 알 수 있습니다.
SQL로 데이터를 조인, 종합 등의 연산을 하면 어떤 일이 발생하는가
일반적으로 Flink에서 SQL을 사용하는 과정에서는 특정 카탈로그, 데이터베이스 혹은 테이블을 생성하거나 파일, 메시지 브로커로 Sink 할 테이블을 만든 뒤 Insert로 입력하게 됩니다. 그리고 그 중간에 조인, 종합 등의 연산이 포함 될 수 있습니다.
우리는 동적 테이블에 대한 이해가 있기 때문에 테이블이 지속적으로 업데이트되는 사실을 알고 있습니다. 업데이트가 된다는 사실은 지금까지의 정보를 Flink 내에서 관리하고 있다는 사실도 알고 있습니다. 그리고 이 과정에서 발생 할 수 있는 메모리 이슈등을 방지하기 위해 TTL등을 지원하는 것도 알고 있습니다.
처음 우리의 문제는 다음과 같습니다.
- SQL을 이용해서 두 테이블을 외부 저장소에서 읽어온다.
- 두 테이블을 조인한다.
- 결과를 ARRAY_AGG 연산으로 종합한다.
- Kafka에 Sink 한다.
Table API(SQL)에서 상태는 어떻게 관리 되는가
Flink 공식 문서에서 이러한 상태 관리 연산에 대한 내용이 포함되어 있습니다. 일반적으로 SELECT 문과 같은 단순 연산에는 따로 상태를 관리하지 않고 현 시점의 동적 테이블에 대한 내용을 모두 출력합니다. 하지만 조인, 종합 등의 연산을 수행 할 때는 과거의 정보를 기반으로 조인이 실행되어야 실시간으로 업데이트되는 정보를 출력하기 때문에 상태를 관리하게 됩니다.
상태를 유지 할 연산은 Flink가 자체적으로 판단하고 저장합니다. 예를들면 일반적으로 소스 데이터는 상태를 저장하지 않지만, 조인이나 종합등의 연산이 포함 될 경우 상태를 저장합니다. 다음은 예시입니다.
CREATE TABLE doc (
word STRING
) WITH (
'connector' = '...'
);
CREATE TABLE word_cnt (
word STRING PRIMARY KEY NOT ENFORCED,
cnt BIGINT
) WITH (
'connector' = '...'
);
INSERT INTO word_cnt
SELECT word, COUNT(1) AS cnt
FROM doc
GROUP BY word;
이 연산에서 word_cnt 테이블은 cnt를 지속적으로 증분 및 관리해야 하기 때문에 상태를 저장합니다. 그리고 이 경우 doc을 복구하는 과정에서도 word_cnt의 정합성을 유지해야하기에 소스 데이터임에도 doc의 상태 또한 저장합니다.
발생한 문제에 대한 원인
이제 발생 한 문제에 대한 정확한 설명이 가능합니다. 다음의 순서로 발생하는 일에 대해 설명하겠습니다.
- SQL을 이용해서 두 테이블을 외부 저장소에서 읽어온다.
- 두 테이블을 조인한다.
- 결과를 ARRAY_AGG 연산으로 종합한다.
- Kafka에 Sink 한다.
SQL을 이용해서 두 테이블을 외부 저장소에서 읽어온다.
이 과정에서 각 데이터는 다음의 특징을 가지게 됩니다.
- 동적 테이블의 형태를 가지고 있다.
- 지속적으로 업데이트 된다.
- 과거 상태를 가지고 있다.
- Flink의 스트리밍 시스템에 따라 각 레코드 단위로 업데이트 된다.
그러면 df_a와 df_b는 각 레코드를 하나씩 읽어오는 중입니다. 특히 출연정보를 나타내는 df_b는 단일 레코드 단위로 늘어나고 있습니다. 이때의 소스 테이블의 상태는 일반적인 경우 모두 저장하지 않습니다.
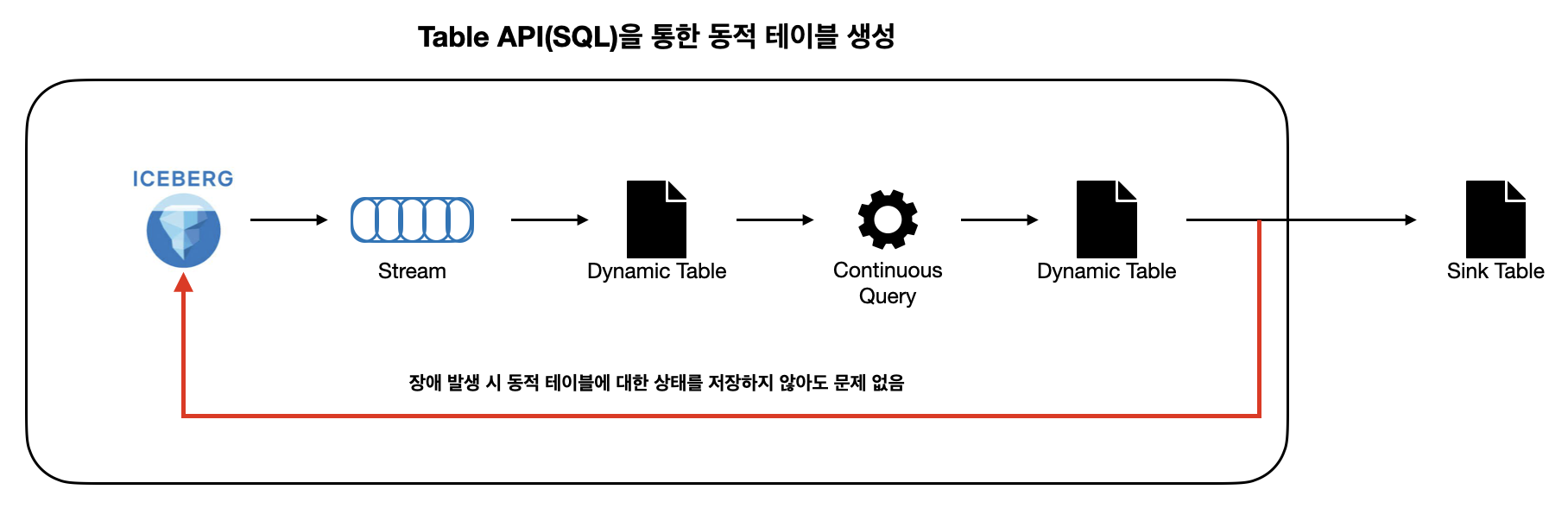
두 테이블을 조인한다.
이 연산부터 상태에 대한 저장이 필요합니다.
두 테이블의 조인 결과가 동적 테이블로 만들어지면서 해당 테이블은 Flink Job에 장애가 발생하더라도 테이블 내용이 유지되어야 하고, 지속적인 업데이트가 필요합니다. 즉 조인 결과 동적 테이블은 상태가 모두 저장됩니다. 마찬가지로 이러한 결과를 일정하게 얻기 위해서는 두 소스 테이블도 모든 상태가 저장되어야 합니다.

위 그림에서 두 소스 테이블은 상태를 유지하면서 지속적으로 업데이트 되는 동적 테이블 임을 이미 공부했습니다. 그리고 조인 한 결과 테이블 또한 동적 테이블이기에 개별 레코드에 가까운 데이터가 업데이트 되면서 조인 된 결과가 조인 테이블에 지속적으로 업데이트 됩니다.
이 결과를 발생 한 문제 기준으로 알아보면 다음과 같은 결과가 나타 날 수 있습니다.
# df_b left join df_a
program_name person_id person_name
0 1박 2일 1 인물 1
1 무한도전 1 인물 1
2 무한도전 2 Null
2 무한도전 2 인물 2
3 라디오스타 3 Null
3 라디오스타 3 인물 3
4 전지적 참견 시점 3 Null
.. ... ...
.. 라디오스타 98 Null
.. 라디오스타 98 인물 98
.. 나 혼자 산다 98 Null
.. 나 혼자 산다 98 인물 98
.. 나 혼자 산다 99 Null
.. 나 혼자 산다 99 인물 99
.. 놀면 뭐하니 99 Null
.. 놀면 뭐하니 99 인물 99
.. 1박 2일 100 Null
.. 1박 2일 100 인물 100
위와 같은 결과가 나오는 이유는 데이터가 순차적으로 입력된다는 가정하에 아직 df_a의 동적 테이블에 df_b 기준으로 person_id가 매칭되지 않는 시점에 조인이 이루어지고 df_a가 지속적으로 업데이트 되면서 df_b와 df_a의 조인 결과가 점차 최종 조인 결과로 나아가기 때문입니다. 즉, 위 테이블의 가장 최종 형태는 우리가 원하는 조인 결과로 얻어집니다.
조인 결과를 ARRAY_AGG 연산으로 종합한다.
위에서 예시 데이터를 보면 즉시 알 수 있는 사항이지만, 이 연산 과정에서도 결과가 동적 테이블로 지속적으로 업데이트되며 그 과정에 모두 결과로 출력됩니다.
위 데이터를 보면 df_a가 업데이트 되기 전까지 조인 결과는 최신 결과를 나타내지 않으며, 그 중간 과정에 대한 모든 데이터를 가지고 있음을 알 수 있습니다. 이 상태 그대로 ARRAY_AGG 연산을 수행하면 처음 우리가 보았던 그 결과가 출력 될 것 입니다.
program_name person_name_list
0 1박 2일 [인물7, 인물14]
1 1박 2일 [인물7, 인물14, 인물15]
2 1박 2일 [인물7, 인물14, 인물15, 인물19]
3 1박 2일 [인물7, 인물14, 인물15, 인물19, 인물20]
4 나 혼자 산다 [인물16]
5 나 혼자 산다 [인물16, 인물26]
6 나 혼자 산다 [인물16, 인물26, 인물29]
7 놀면 뭐하니 [인물4]
7 놀면 뭐하니 [인물4, 인물9]
...
이러한 결과도 결과적으로 최종 테이블에 맞추어 업데이트 되어 갑니다.
Kafka에 Sink한다.
가장 큰 문제가 있다면 이 부분임을 알 수 있습니다. 만약 program_name을 PK로 설정 한 뒤 Database에 저장한다면 사실 위 문제는 그리 큰 문제가 아닙니다. 하지만 Kafka라는 메시지(레코드) 단위의 데이터 전달은 이러한 최종적 정합성 보장에 어려움을 줄 수 있습니다. 이런 이유로 조인,종합 과정에서 얻었던 중간 결과가 모두 kafka topic으로 보내져서 문제가 발생한 것입니다.
참조
- https://nightlies.apache.org/flink/flink-docs-release-1.20/docs/dev/table/concepts/overview/