FastText 모델을 이용한 유사한 Document 찾기
1. FastText 란?
FastText는 FaceBook의 AI개발팀에서 만든 Word Embedding 방법입니다. 이 방식은 이전에 다루었던 Word2Vec과 유사하므로 한번 참고하고 오면 이해하기 쉬울 수 있습니다.
1 - 1 ) 왜 FastText가 만들어졌나
FaceBook과 같은 SNS에서는 완전한 단어로 만들어진 문장이 아닌 자연어로 이루어진 경우가 많습니다. 이러한 문장에서는 단어를 Token화 시킬 경우 동일한 의미를 갖는 단어임에도 다르게 분류되기 마련입니다.
예를 들어 [‘나이값’,’나잇값’,’나잇갑’,’나이갑’] 이라는 단어들을 사용한 문장이 있다고 가정합니다. 모두 나잇값의 의미를 갖는 단어들이지만 모두 스펠이 다르다는 이유로 다른 단어로 생각하게 됩니다.
BagOfWords의 경우에는 [1,0,0,0] [0,1,0,0] [0,0,1,0] [0,0,0,1] 처럼 모든 단어를 독립성을 가진 채로 표현합니다. 이 경우 예시의 모든 단어는 각자 아예 다른 단어로 인식하게 되겠네요.
Word2Vec을 기준으로 살펴봅시다. 네 단어 모두 같은 의미를 가지고 있으며 사용하는 상황이 일치합니다. 오히려 오타에 가까운 수준이죠. 그렇가면 네 단어는 모두 비슷한 벡터를 갖게 되는 것을 쉽게 생각할 수 있습니다만 위 예시에서 정답에 가까운 단어는 나잇값입니다. 그러면 나머지 세 단어는 낮은 빈도로 등장하게 되죠.
이 경우 Word2Vec의 단점이 나타납니다. 너무 낮은 빈도로 등장한 단어들에 대해 제대로 된 학습이 진행되지 않는 단점입니다.
학습을 진행하는 과정에서 낮은 빈도로 등장하는 단어도 다른 단어와 마찬가지로 학습이 진행됩니다. CBOW 든 Skip-Gram이든 해당 단어는 유사한 단어를 향해 나아가는 것은 맞습니다만 문제는 그 학습의 빈도로 극도로 낮다는 점입니다.
학습의 타겟이 되는 빈도는 극도로 낮지만 Word2Vec에서 정답이 아닌 단어에 대해 거리를 넓히는 과정에서 negative Sampling에 걸릴 확률은 언제나 있습니다. 예를 들어 1M개의 문장에서 “나이갑”이라는 단어가 단 2번 등장했다면 1M 번 학습 중 단 2문장에서 학습이 진행되며 나머지 (1M - 2) 문장에서는 나이값이라는 단어를 먼 벡터로 떨어뜨리기 위한 negative Sampling에 포함 될 확률이 있습니다.
이 경우 “나이갑”이라는 단어의 벡터가 올바르지 않는 자리에 있을 확률이 꽤나 높습니다. 그러면 만약 나이갑이라는 단어가 분류하고자 하는 input값으로 들어올 경우 잘못된 답을 내놓을 수 있고, 군집화도 제대로 되지 않을 수 있습니다.
또한 [‘나이값’,’나잇값’,’나잇갑’,’나이갑’] 이라는 단어들은 모두 공통된 의미이며 누군가는 이런 값들의 입력으로 “나잋값” 이라고 입력 할 수 있습니다. 물론 이 경우 국어를 먼저 배우는 과정이 필요하겠지만, 자연어는 모든 일이 일어날 수 있는 세상이므로 가정하겠습니다. 이 경우 기존의 Embedding을 통해 나온 모든 모델은 OOV에러를 발생시킵니다.
OOV에러는 Out Of Vocabulary 에러를 나타내며 즉 학습한 모델에는 해당 단어가 벡터화 되지 않았다는 것을 나타냅니다. “나잋값”이라는 단어를 학습 시 사용되지 않았으니 값을 찾지 못한다는 말입니다.
이러한 두 문제점을 해결하기 위해 FastText는 등장했습니다.
1 - 2 ) FastText 방식
FastText는 유사한 형태의 단어들을 유사한 벡터로 표현하기 위해서 또한 OOV 문제를 해결하기 위해 단어를 더욱 작은 단위(글자 혹은 자모)로 나누어서 학습하는 방식을 제안합니다.
예를 들면 “아이스크림” 이라는 단어를 Embedding 할 경우 기존에는 통째로 학습했었다면 FastText는 [“<아이”,”아이스”,”이스크”,”스크림”,”크림>”] 과 같은 window 크기를 기준으로 잘라서 학습시킵니다. 문장의 처음과 마지막에 있는 [”<”,”>”] 을 사용하는 이유는 단어의 시작과 끝을 나타내주기 위해서 입니다.
그리고 모든 단어들의 벡터의 평균을 내주면 아이스크림의 벡터값이 나오는 방식으로 진행됩니다. 단어의 부분집합을 이용하여 해당 단어의 벡터값 을 구하는 방식이라고 생각할 수 있습니다.
이러한 방식을 이용하면 다음과 같은 예시에서 효과적인 벡터를 얻을 수 있습니다.
아이스크림 아이스커피 아이스크림빵
[“<아이”,”아이스”,”이스크”,”스크림”,”크림>”][“<아이”,”아이스”,”이스커”,”스커피”,”커피>”][“<아이”,”아이스”,”이스크”,”스크림”,”크림빵”,”림빵>”]
아이스크림과 아이스커피는 2개의 단어가 겹치는 부분이 있으므로 어느정도 연관성이 있다는 것을 알 수 있고, 마찬가지로 벡터로 표현이 될 것입니다. 그리고 아이스크림과 아이스크림빵은 4개의 단어가 겹치므로 더 큰 연관성이 있을 것임을 알 수 있습니다.
하지만 더 작은 부분조합으로 나타낼 수 있습니다. 예를 들면 자음과 모음을 각자 분리시키면 어떨까요? 자음과 모음으로 나누면 다음과 같은 형태가 됩니다. 받침이 없는 경우 - 로 표현합니다.
[‘ㅇ’,’ㅏ’,’-‘,’ㅇ’,’ㅣ’,’-‘,’ㅅ’,’ㅡ’,’-‘,’ㅋ’,’ㅡ’,’-‘,’ㄹ’,’ㅣ’,’ㅁ’][‘ㅇ’,’ㅏ’,’-‘,’ㅇ’,’ㅣ’,’-‘,’ㅅ’,’ㅡ’,’-‘,’ㅋ’,’ㅓ’,’-‘,’ㅍ’,’ㅣ’,’-‘][‘ㅇ’,’ㅏ’,’-‘,’ㅇ’,’ㅣ’,’-‘,’ㅅ’,’ㅡ’,’-‘,’ㅋ’,’ㅡ’,’-‘,’ㄹ’,’ㅣ’,’ㅁ’,’ㅃ’,’ㅏ’,’ㅇ’]
이렇게 구분했을 경우에는 [‘ㅇ’,’ㅏ’,’-‘,’ㅇ’,’ㅣ’,’-‘,’ㅅ’,’ㅡ’,’-‘,’ㅋ’] 까지는 모두 같은 벡터를 갖게 됩니다. 마찬가지로 학습을 시킬 경우에는 양 옆에 ‘<’ , ‘>’ 로 구분하여 부분집합 형태로 잘려져서 학습을 거치게 됩니다.
유사한 단어가 더 세밀하게 벡터 연산을 거치게 되어 유사한 정도를 더욱 잘 표현 할 수 있습니다.
나잇값과 유사한 단어 셋도 공통적으로 나이라는 단어가 들어갑니다. “잇”이나 “잋”도 자음 모음으로 나누어보면 [‘ㅇ’,’ㅣ’,’ㅅ’] 과 [‘ㅇ’,’ㅣ’,’ㅊ’] 으로 나눌 수 있으니 결국 모두 나이라는 단어가 포함되어 있다고 볼 수 있습니다.
만약 “나이”라는 단어 자체에 대해 점수를 줄 수 있다면 “나잇”도 유사한 점수를 줄 수 있고 “나잋”이라는 단어도 점수를 줄 수 있습니다. 어찌됬건 유사한 것은 마찬가지니까요.
2. 어떻게 유사한 Document를 찾을까
유사한 Document를 찾아가는 방법으로 가장 널리 알려진 방법은 Doc2Vec입니다. Doc2Vec은 Word2Vec의 방식을 조금 변형하여 Document ID 를 학습 데이터로 추가하여 각 학습을 거쳐가면서 Document ID는 문장을 대표하는 벡터에 위치하게 됩니다.
하지만 Word2Vec과는 조금 다르게 FastText는 단어를 형성하는 부분집합을 학습데이터로 사용하는 경향이 있습니다. 실제로 모델을 Doc2Vec과 같이 Document ID를 추가하여 비슷한 방식으로 구현한다면 어느정도의 결과를 얻을 수 있겠지만, 아직 그 정도의 실력은 아니라 다른 방식을 사용해봅니다.
2 - 1 ) 단어 벡터의 평균을 이용
문장은 단어로 이루어져 있으며 FastText를 사용한다면 OOV 문제는 해결 되었습니다. 그러므로 모든 단어의 벡터를 합친다면 해당 문장의 벡터로 사용할 수 있지 않을까? 라는 생각으로 문장을 이루는 모든 단어의 벡터를 평균내는 방식을 사용해보았습니다.
def get_document_vector(self,text):
return np.array([self.model.get_word_vector(x) for x in text.split(' ')]).mean(axis=0)
여기서 model이란 원하는 데이터로 사전 학습 된 FastText모델을 말합니다. 한 문장을 공백 기준으로 나누어서 각 단어의 벡터를 구한 뒤 평균을 구합니다. 벡터를 합하지 않은 이유는 문장마다 단어의 수가 다르기 때문에 스케일이 달라질 수 있기 때문입니다.
이러한 방식으로 단어의 벡터를 이용하여 해당 문장의 벡터를 얻어냈습니다. 만약 직접 Doc2Vec을 구현하여 문장의 벡터를 구한다면 이러한 방식보다 조금 더 유연한 모델을 만들 수 있지만, 구현의 편의성으로 언젠가 따로 만들도록 하겠습니다.
2 - 2 ) KNN 방식 이용
가장 가까운 요소를 찾으시오. 라는 문제에서 가장 먼저 생각나는 방식은 K-NearestNeighbor 를 떠올릴 수 있습니다. 그만큼 명확한 방법이며, 간단한 방법으로 말 그대로 특정 거리공식에 따라 가장 가까운 요소를 찾는 기능을 가지고 있습니다.
간단한 예를 들면 다음의 방식에 따라 작동합니다.
- 한 벡터를 선택한다.
- 다른 점까지의 거리를 모두 계산한다.
- 가장 가까운 K개를 선택하고 그 중 가장 많은 라벨을 자신의 라벨로 추정한다.
그림으로 보면 다음과 같습니다.
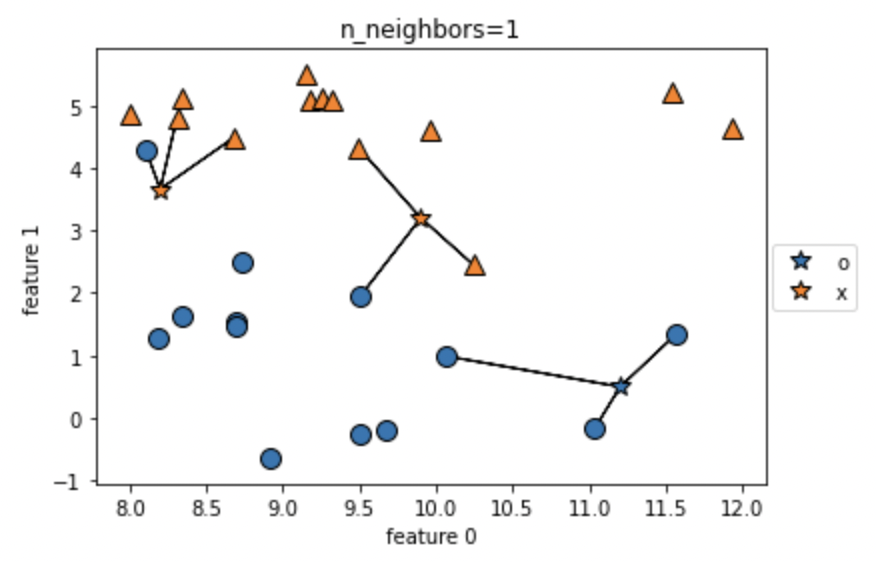
가장 간단한 방법이며, 구현도 쉽지만 큰 문제는 계산 횟수의 문제입니다. 이 방식은 N^2의 시간 복잡도를 가지고 있습니다. 왜냐하면 모든 점에 대해 가장 가까운 점을 찾기위해 모든 점과의 거리를 계산해야 하기 때문이죠. KNN은 간단하지만 강력한 방법으로 많이 사용되어 지면서 이러한 계산 속도를 줄이는 방법은 다양하게 발전해왔습니다.
추후에 KNN만을 다루는 방법과 다양한 기법에 대해 공부하여 포스팅하도록 하겠습니다.
이렇게 거리를 구하는 방법은 BagOfWords 형식의 임베딩 방식에서는 사용하기 어렵습니다. 그 이유는 Sparse Matrix이기 때문이죠. 연산하는 횟수도 방대해질 뿐 아니라 대부분의 값이 0이 될 것입니다. 단어가 겹치지 않는 경우가 많으니까요. 기껏 사용하더라도 고작 같은 단어가 얼마나 나오는가? 에 대한 답밖에 되지 않습니다.
하지만 FastText나 Word2Vec같은 Distributed Representaion은 이런 문제를 해결할 수 있습니다. 모든 단어를 제한 된 사이즈의 벡터로 표현하며 심지어 유사한 단어를 어느정도 반영하고 있기 때문이죠. 유사한 위치에 사용 된 단어들의 벡터는 가까운 거리를 가지고 있을 것이고, 이 때문에 KNN을 사용했을 경우 K개 안에 포함 될 가능성이 높아지죠.
그럼 한번 도전해보겠습니다.
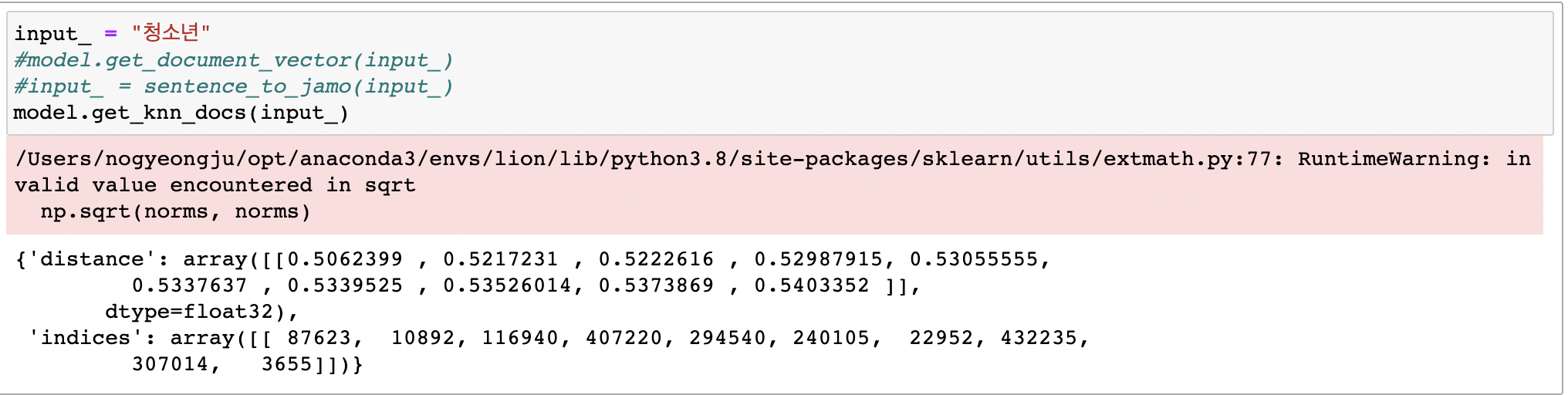
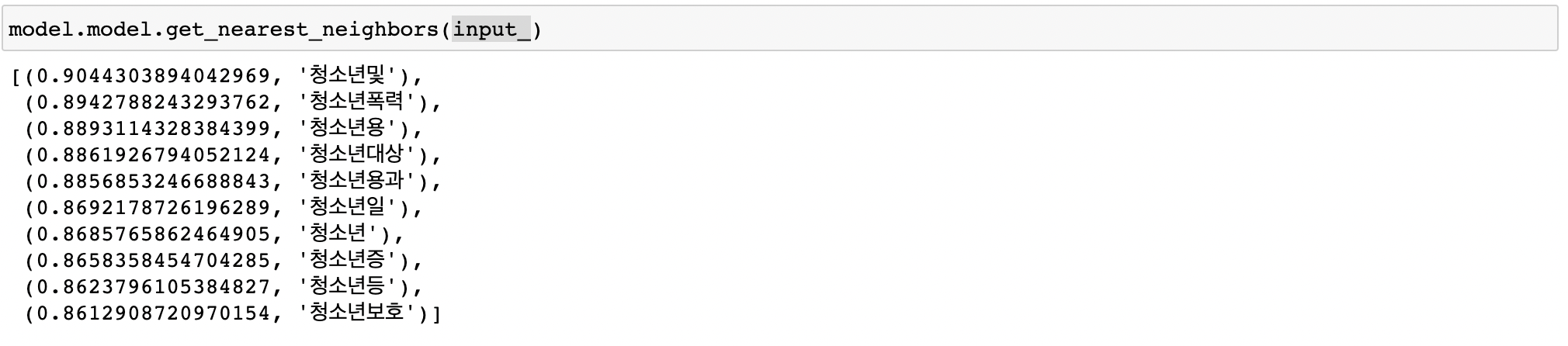



다음과 같이 성공적으로 찾아낼 수 있었습니다.
2 - 3 ) 단어 단위의 벡터 비교를 통한 유사한 문장 찾기
KNN을 이용하면 비슷한 문장을 찾아 낼 수 있습니다. 하지만 제가 하고 싶은 것은 제가 입력하는 문장에 대해 비슷한 문장을 찾아내고 싶었습니다. 입력하는 값의 길이가 짧건 길건 말이죠.
입력 값으로 비슷한 문장을 찾으려고 KNN을 사용해보았습니다. 같은 모델로 벡터를 구하고 거리를 계산하는 것까지 동일하게 진행했음에도 결과가 그리 좋지 않았습니다.
제가 생각하는 가장 큰 이유는 입력하는 (혹은 찾으려는) 문장은 대부분 목적을 가진 하나의 키워드와 같은 가중치를 가지지만 문장의 벡터는 다양한 단어들의 평균으로 이루어져 있기 때문에 흔들리기 때문입니다.
물론 단어를 나타내는 차원의 수가 크면 클수록 하나의 단어가 가진 가중치가 조금 더 부각되는 (조금 더 독립성을 갖는) 모델이 될 수 있지만 차원이 커질수록 메모리 사용량이나 연산에 필요한 시간 또한 늘어나며 독립성이 강해지면 결국 BagOfWords와 비슷하게 표현될 수 있습니다.
그래서 저는 단어를 기반으로 찾는 방법을 고안했습니다. 저는 텍스트 분석을 공부하면서 들었던 말 중 다음의 말이 상당히 인상 깊었습니다.
“분류 문제에서 텍스트 분석은 특정 단어의 사용여부만으로도 가능하다. 왜냐하면 독립성이 강하다는 특징이 텍스트가 가진 큰 특징이기 때문이다. 수 십년간 BagOfWords 방식으로 분석을 해 왔던 이유도 그런 이유다.”
결국 단어의 유무만으로도 분류가 가능했던 이유가 독립성이 있기 때문입니다. 하지만 우리는 Word2Vec을 공부하면서 단어를 독립적인 하나의 차원이 아닌 다차원의 복합적인 상관관계로 표현할 수 있게 되었습니다.
중요한 점은 단어를 표현 할 수 있게 되었다는 점 입니다.
그럼 우리는 단어를 이용하여 입력한 텍스트와 비슷한 문장을 찾아보겠습니다. 방식은 간단합니다. 문장은 다음과 같은 형식으로 이루어져있습니다.
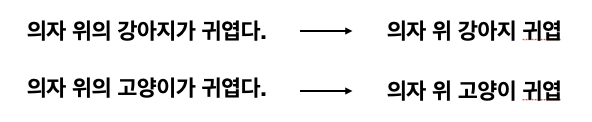
이러한 형태를 BagOfWords 형태로 나타내면 다음과 같습니다.
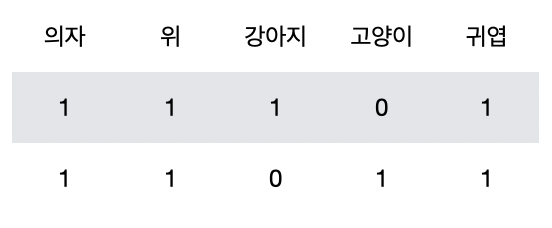
마찬가지로 이번엔 Word2Vec 형태로 표현해보도록 하겠습니다.
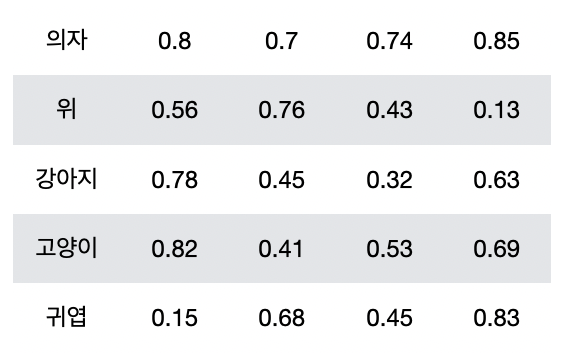
여기서 우리가 주목할 점은 1차원의 형태에서 2차원으로 문장을 표현 할 수 있게 된 점입니다. 그렇기에 우리는 CNN과 같은 기법을 텍스트에 적용할 수 있게 된 것이죠. 그러면 유사한 문장을 찾는 과정도 이러한 방법을 이용하는건 어떨까요?
문장에서 특정 단어를 찾는 것 만으로 문장을 분류 할 수 있는 특징
단어가 하나의 0차원 값이 아닌 1차원의 벡터로 표현 할 수 있는 기법
이 두 특징을 이용하여 찾고자 하는 문장의 단어들과 찾을 대상의 문장의 단어들의 거리를 비교하여 가장 가까운 값을 선택하면 유사한 문장을 찾을 수 있지 않을까? 라는 아이디어로 만들어보았습니다.
def get_similar_key_docs(self,X,Y,N=10,dist_func = 'cosine'):
#아래의 공식의 값을 max_heap에 넣으면 됨 maxheap의 크기는 N을 입력받고 ㄱㄱ
#np.min(fd2v.get_similar_key_docs(input_,'ㅊㅓㅇㄴㅕㄴㅇㅡㄴ ㅇㅓㄷㅣㅇㅔㅅㅓ ㅇㅣㄹㅎㅏㄴㅏㅇㅛ'), axis=1).sum()
heap = []
for idx,text in enumerate(Y):
dist = np.min(pairwise_distances(self.get_word_vectors(X),self.get_word_vectors(text),metric = dist_func),axis=1).sum()
if(len(heap) < N):
heapq.heappush(heap,(-dist,dist,idx))
elif(dist < heap[0][1]):
heapq.heappop(heap)
heapq.heappush(heap,(-dist,dist,idx))
return heap
정확히 위의 코드는 비슷한 문장을 찾는 방식 이 아닌 입력한 문장에 속한 단어와 가장 비슷한 단어들을 사용한 문장 을 얻는 알고리즘입니다.
하지만 문제점으로는 너무나 많은 연산을 요구합니다.
\[(N*V) \times (V*W)\]모든 문장에 대해 위의 행렬연산을 거치게 되고 그 값 중 가장 작은 값을 Heap에 저장하게 됩니다. 입력한 키워드들이 각 문장에 존재한다면 dist는 작은 값을 가질 것이고, 정확히 같지 않더라고 비슷한 의미를 가진 단어가 문장에 존재하면 상대적으로 가까운 위치에, 완전히 의미없는 문장의 경우에는 먼 거리에 위치하게 될 것입니다.
출처
- https://ratsgo.github.io/machine%20learning/2017/04/17/KNN/