Doc2Vec 을 이용한 Clustering
Doc2Vec은 Word2Vec이 제안된 지 얼마 지나지 않아 비슷한 방식을 이용하여 문장도 벡터화 시킬 수 있는 방식으로 제안되었습니다. 실제로도 Word2Vec을 진행하는 과정과 비슷하게 작동하는 것을 볼 수 있고, 이 방식으로 인해 문서 군집화를 단순한 단어의 유무(BagOfWords)를 이용하는 방식에서 문장의 의미적인 측면에서 유사한 문서의 군집을 얻을 수 있는 희망이 생겼습니다.
이전의 포스팅에서는 Clustering 하는 과정에서 단순 TF-IDF 개념을 이용하여 군집화 하는 방식을 보여드렸지만 이번 포스팅에서는 Doc2Vec을 이용하여 군집하는 과정을 적어보겠습니다.
Clustring
자세한 Clustering의 설명은 이전 포스트에 있습니다.
요점으로 Clustering이 진행되는 과정을 가져와서 설명하겠습니다.
- k개의 Representation Point를 임의의 요소의 벡터로 선택한다.
- 전체 데이터에 대해 Representation Point와의 거리를 계산한다.
- 해당 데이터의 군집을 가장 가까운 거리에 있는 Representation Point와 같은 군집으로 할당한다.
- 각 군집의 Representation Point를 해당 군집을 가진 데이터의 평균으로 업데이트한다.
- 전체 데이터를 기반으로 2-4단계를 다시 진행한다.
데이터를 가장 잘 군집화 하는 Representation Point를 찾아가는 과정이 바로 K-means 군집화입니다. 제대로 위치를 찾아내면 각자 자신의 주변 데이터에 대해 군집화하기만 하면 각 군집에 속한 데이터를 찾을 수 있는 것이죠.
이전의 Clustering을 하는 과정에서는 Cosine distance를 이용해서 Representation Point에서 각 점으로 distance를 구했습니다. 그 이유는 텍스트 데이터의 경우 각 데이터들이 독립적이며 단어 하나하나가 차원을 나타내기 때문에 euclidean 거리로 계산했을 때 가까운 거리를 잘 나타내더라도 거의 대부분의 데이터가 먼 거리로 표현되기 때문입니다.
하지만 이번 Clustering에서는 Cosine distance보다 euclidean distance를 우선시하여 사용할 예정입니다. 그 이유는 Doc2Vec을 사용하면 각 문장을 벡터 공간에 놓음으로써 원하는 차원으로 압축 할 수 있기 때문입니다. 물론 두 방식을 모두 할 생각입니다.
그리고 추가적으로 Pearson Correlation ( 상관계수 )도 포함해서 진행해볼 예정입니다. 벡터 공간에서 비슷한 단어들을 사용했을 때 각 벡터의 순서도 비슷할 것이라고 생각이 들어서 한 번 해보겠습니다.
Doc2Vec
Doc2Vec에 대해 공부해보겠습니다.
Doc2Vec은 이전의 Word2Vec을 응용하여 문장 내 단어의 유사성을 벡터로 표현하는 것을 넘어 문장 간의 유사성을 벡터로 표현하는 방법입니다.
일단 Word2Vec에 대한 설명은 이전 포스트에 있습니다.
1. Word2Vec
Word2Vec을 간단히 말하면 ‘주변 단어들이 비슷한 형태를 띄고 있는 단어들은 비슷한 의미를 가지고 있지 않을까?’ 입니다.
[‘의자’,’앉’,’개’,’사료’,’먹는’] [‘의자’,’앉’,’고양이’,’사료’,’먹는’] 다음과 같은 두 단어의 배열로 이루어진 문장이 있다면 주변 단어가 동일하게 사용 된 개와 고양이가 어느정도 비슷한 의미를 가진다는 점을 알 수 있습니다.
주변 단어를 이용하여 해당 단어를 얻는 방법, 즉 Word2Vec을 사용하는 방법으로 2가지 방식이 있었습니다. 한가지는 Cbow와 다른 하나는 Skip-gram 방식이였습니다.
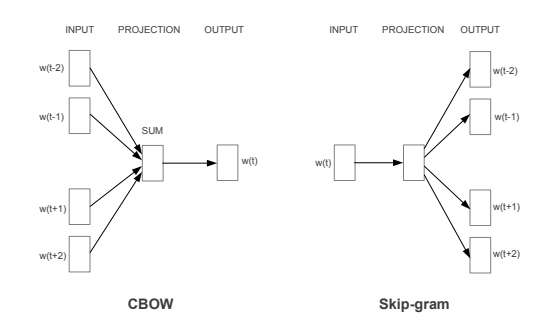
- CBOW 방식은 주변 단어를 Input으로 해당 단어를 Output으로 작동하는데 이해하기 쉽게 주변단어의 벡터의 위치와 근접하게 해당 단어의 벡터를 옮긴다고 생각하면 됩니다. 예시에서 설명한 개와 고양이로 예시를 들면 [‘의자’,’앉’,’사료’,’먹는’] 의 방향으로 [‘개’] 의 벡터를 옮기고 마찬가지로 [‘고양이’] 벡터를 옮기면 두 벡터는 비슷한 방향으로 이동하기 때문에 [‘개’] 벡터와 [‘고양이’] 벡터는 가까이에 위치하며 이 결과를 우리는 개와 고양이는 유사성이 있다. 로 받아들입니다.
-
Skip-gram 방식은 해당 단어를 Input으로 주변 단어를 Output으로 작동하는데 해당 단어의 벡터 방향으로 주변 단어의 방향을 옮긴다는 의미가 됩니다. 여기서 간단히 생각하면 [‘개’]와 [‘고양이’] 는 벡터가 움직이지 않고 주변 벡터를 끌고온다는 생각을 할 수 있습니다. 하지만 두 단어도 중심단어로 사용되기 이전에 주변단어로 사용되고 이후에도 주변 단어로 사용한다는 점에서 벡터 이동이 생깁니다.
-
[‘개’] 와 [‘고양이’]는 가장 먼저 [‘의자’]에 가까워지고 [‘앉’]에 가까워지며 이후 [‘의자’,’앉’,’사료’,’먹는’]을 끌고오며 [‘사료’]와 가까워지고 [‘먹는’]에 가까워집니다.
실제로 일반적으로 Skip-gram이 높은 성능을 보인다고 말하기도 합니다.
참고자료
https://arxiv.org/pdf/1301.3781.pdf
2. Doc2Vec의 아이디어
Doc2Vec의 아이디어는 Word2Vec의 아이디어에서 단어의 벡터를 옮기는 부분에서 생겨납니다.
Word2Vec은 중심단어를 기반으로 WindowSize 만큼 주변 단어를 탐색하면서 벡터 이동을 통해 유사한 단어들을 찾아가게 됩니다. 그러한 과정 중 모든 단어들은 유사한 단어들과 비슷한 벡터로 자리잡게 되는데, 그 과정에서 Document ( 논문에서는 Paragraph로 표기합니다 ) 벡터를 추가하여 벡터를 같이 이동시키게 된다면 Document 자체적으로 벡터값을 가질 수 있게 되는 아이디어 입니다.
예시를 들어 설명하겠습니다.
[‘의자’,’앉’,’개’,’사료’,’먹는’]
[‘자리’,’누워’,’고양이’,’먹이’,’먹는’]
다음과 같이 ‘의자’라는 단어를 ‘자리’로 바꾸거나 ‘사료’라는 단어를 ‘먹이’로 바꾸었을 때 서로 관련성이 있는 단어임은 쉽게 알 수 있습니다. 학습 데이터에서도 두 단어의 주변 단어가 비슷하게 분포되었다는 가정을 하면 Word2Vec에서도 각각의 단어들은 비슷한 벡터를 가질 것임은 지금까지 내용으로 알 수 있습니다.
문제는 두 문장은 유사한 문장인가? 입니다.
가장 먼저 Distributed Memory 방식이 있습니다.
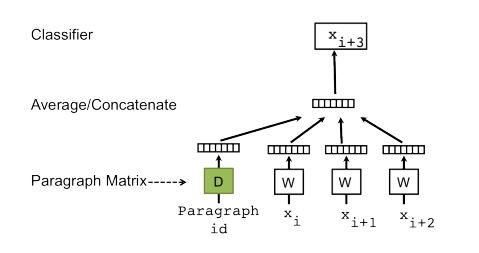
위의 그림에서 등장하는 Document id( = Paragraph id )에 주목할 필요가 있습니다. 이 값으로 얻어내는 벡터가 바로 Document 벡터입니다.
Distributed Memory는 문서 자체의 벡터와 순차적으로 등장하는 단어를 Input하여 다음 단어를 예측하는 모델입니다. 예측한다는 말을 softmax를 통해 계산 된 값을 기반으로 Backpropagation을 이용하여 해당 단어 벡터를 Input 벡터 방향으로 끌어당긴다. 라고 이해하시면 됩니다.
그렇게 되면 다음과 같은 그림이 됩니다.
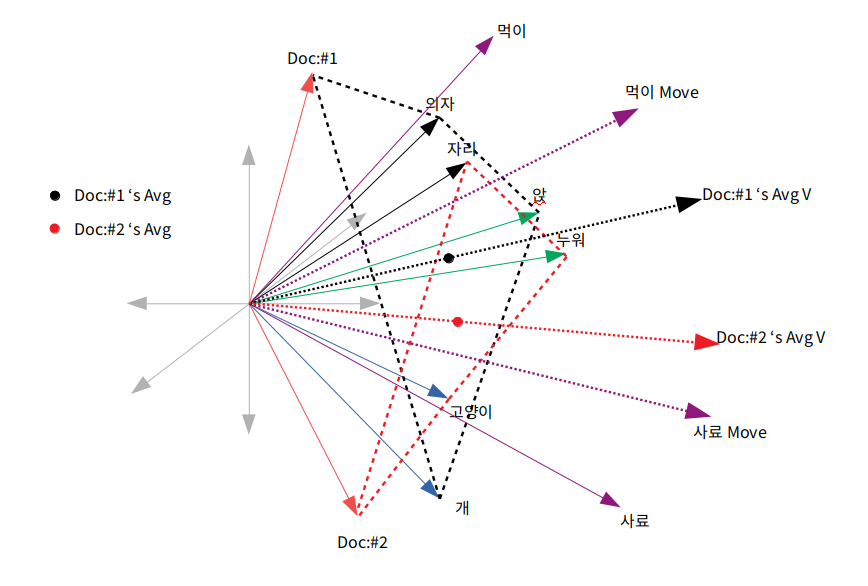
순차적으로 이와 같은 계산을 하게 되면 단어들과 Document id 벡터의 연관성이 생기게 되며 Word2Vec과 마찬가지로 여러 문장들에서 많이 나온 단어들에 대해서는 여러 Document로 끌려가는 성질이 있기 때문에 벡터가 멀어지는 효과도 있습니다. 물론 negative Sampling이 필요할 것 같긴 하지만 말입니다.
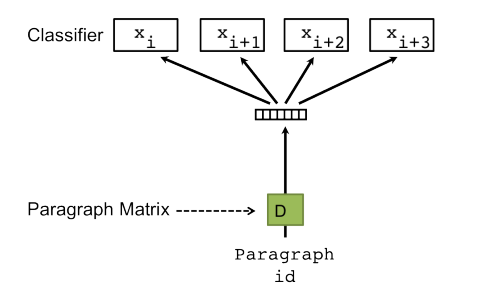
DBOW의 경우에는 저도 지금 공부하는 중입니다. 정확히 모르지만 제가 이해하는 내용을 그림으로 설명해보도록 하겠습니다.
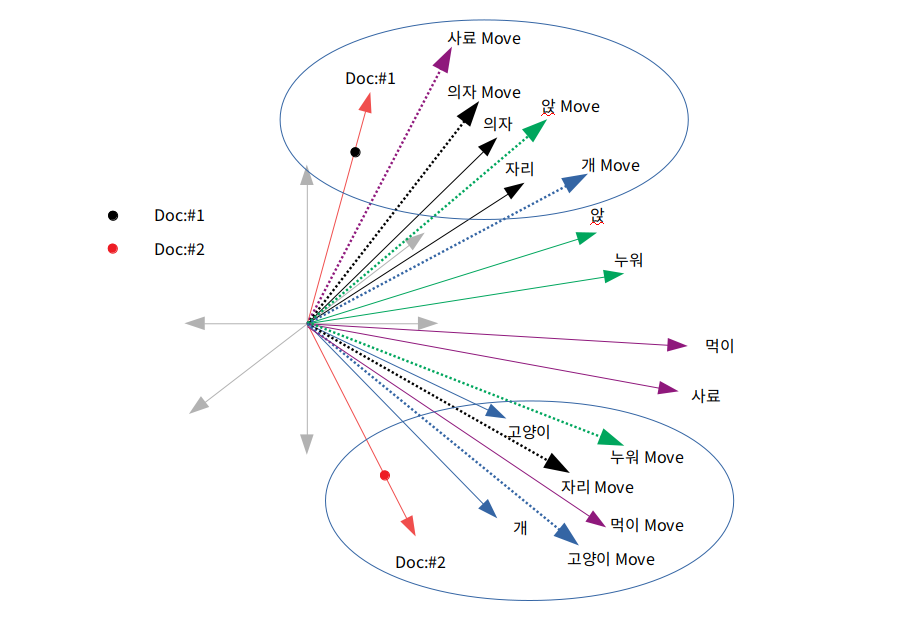
이 경우 문서에 대한 벡터를 얻을 수 있지만 단어들간의 유사한 정도가 유지되는지 잘 모르겠습니다. 더 공부해서 이해해보도록 하겠습니다.
Doc2Vec Clustering
그럼 이전 포스팅에서 했던 BagOfWords 기반의 Clustering을 Doc2Vec을 기반으로 진행 해보겠습니다.
k-means 알고리즘 자체는 동일하므로 기존의 소스를 사용하면 될 것 같습니다. 하지만 단어 수가 차원의 수가 아닌 원하는 크기의 차원으로 축소시켰기 때문에 고차원에서 생기는 문제에 대해 어느정도 문제가 해결되었다고 예상하고 BagOfWords 기반의 Clustering 성능 관련 논문에서 효율이 낮았던 euclidean distance도 좋은 성능이 나올 것이라고 생각됩니다.
- 형태소 추출 전 추가적인 단어 추가
- 명사 형태소 추출
- Doc2Vec을 이용하여 문서 데이터를 벡터화
- K-means를 이용하여 문서 군집화
- 라벨링 된 정보를 이용하여 순수도를 기준으로 검증
이러한 순서로 진행해보겠습니다.
1. 형태소 추출 전 추가적인 단어 확보
문장에서 주요한 의미를 가진 형태소인 명사를 추가해보도록 하겠습니다. 이유는 사용하는 데이터가 국민청원의 데이터이므로 뉴스와 같이 보편적인 단어가 아닌 신조어 및 특정 사건등에 대해 이야기 할 확률이 높습니다. 그런 명사들을 얻기 위해 lovit님의 soynlp를 이용하여 명사 추출을 진행합니다.
noun_extractor = LRNounExtractor_v2(verbose=True,min_num_of_features=5)
# Komoran에 추가 할 단어
add_nouns = set()
# 데이터 전체 크기
end = len(content)
# 메모리 부족 현상으로 커널이 닫혀서 batch size로 분할작업
batch = int(end/4)
for i in range(0,end,batch):
nouns_content = noun_extractor.train_extract(content[i:i+batch])
nouns_title = noun_extractor.train_extract(title[i:i+batch])
add_nouns.union(set(nouns_content))
add_nouns.union(set(nouns_title))
f = open("add_userdic.txt",'w')
for i in list(add_nouns):
f.write(i + '\t' + 'NNG'+ '\n')
f.close()
작업 진행중 데이터량이 많아 메모리 부족 현상을 겪게되어 batch size를 지정하여 4분할로 명사를 추출했습니다. 약 8만개 정도 데이터에서 명사를 찾게 되었지만, min_num_of_features가 5이므로 단어가 조금 사라졌을지도 모릅니다. 추후에 min_num_of_features를 낮추어 진행해보도록 합니다.
파이썬에서 Set의 union 등의 함수들은 효율이 안좋기로 유명하긴하지만 실제 모델 작업이 아닌 사전에 진행하는 단어 추가를 위한 작업이므로 set을 이용했습니다.
2. 명사 형태소 추출
텍스트 분석 중 분류 모델을 작성할때는 명사만 추출하더라도 충분한 성능이 나온다는 말을 들은적이 있습니다. 일반적으로 TF-IDF 같은 경우 각각의 단어 자체가 One-hot Vector로 만들어지기 때문에 명사만 추출하는게 옳은 거라고 생각합니다.
마찬가지로 각각의 단어가 하나의 벡터를 갖는 Doc2Vec의 경우에도 비슷한 경우라고 생각되어 명사만 추출해보았습니다. 결과가 좋지 않으면 형용사와 동사를 추가하겠지만, 아무래도 모델이 무거워지기도 하며 문장에서 가장 큰 영향을 끼치는 명사만으로 진행하는 것이 최선이라고 생각됩니다.
추후에 유연성있는 형태소 추출을 위해 관련 클래스를 만들었습니다. 명사만 추출하는 경우에는 Komoran에서 자체 제공하는 nouns 함수를 이용하면 됩니다.
pos = ['NNG','NNP','NNB']
class tagging:
def __init__(self,user_words = ''):
self.kom = Komoran(userdic = user_words)
# lovit 님의 명사 추출을 한 값을 파일 명으로 리턴
def get_nouns(self,sents,result_type = 'list'):
for i,sent in enumerate(sents):
sents[i] = self.kom.nouns(sent)
if(len(sents[i]) == 0):
sents[i] = ['error']
if(result_type == 'list'):
return sents
elif(result_type == 'str'):
return list(map( lambda x:' '.join(x),sents))
else:
print("result_type -> list or str")
return 'error'
def get_pos(self,sents,pos='all',result_type = 'list'):
if( pos == 'all' ):
for i,sent in enumerate(sents):
sents[i] = [word for word,pos_ in self.kom.pos(sent)]
else:
for i,sent in enumerate(sents):
try:
sents[i] = [word for word,pos_ in self.kom.pos(sent) if pos_ in pos ]
except:
sents[i] = ['error']
if(result_type == 'list'):
return sents
elif(result_type == 'str'):
return list(map( lambda x:' '.join(x),sents))
else:
print("result_type -> list or str")
return 'error'
3. Doc2Vec을 이용하여 문서 데이터를 벡터화
Doc2Vec을 사용하기 위해 먼저 해야 할 일은 Document를 서로 구분지어주는 일입니다. TaggedDocument는 [words] [tags] 형태로 바꾸어 줍니다. 여기서 tags의 역할이 바로 document id를 부여하는 것이죠.
공부하면서 참고한 블로그에서는 이 tags에는 여러 태그를 넣을 수 있는데 이 방법으로 분류작업에 유리한 방식으로 설계할 수 있을 것 같아서 참고자료 블로그에 추가했습니다.
Doc2Vec 사용 소스는 아래와 같습니다.
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
tagging_class = tagging(user_words='./add_userdic.txt')
pos = ['NNG','NNP','NNB']
documents = [TaggedDocument(doc, [i]) for i, doc in enumerate(tagging_class.get_pos(content,pos=pos,result_type='list'))]
docModel = Doc2Vec(documents=documents,vector_size=300,window=2)
f = open('./doc2VecModel.pkl','wb')
pickle.dump(docModel,f)
f.close()
각 document를 해당 document의 인덱스로 id값을 부여했습니다.


그 결과는 위처럼 각 document에 등장한 단어들이 각 인덱스로 tagging 된 것을 확인할 수 있습니다. 그 결과를 이용하여 doc2Vec을 사용하면 됩니다.
4. k-means 적용
k-means 알고리즘은 직접 만든 LionClustering을 사용해서 군집화 해보겠습니다. 마침 혼자 공부하면서 구현한 알고리즘을 적용해 볼 기회가 되어 다행입니다.
a = LionClustering(dist_func='euc',cluster_num=300,max_iter=10,stop_rate=0,initialize='entropy')
a.fit(model.docvecs.vectors_docs)
model 변수는 Doc2vec 모델이며 LionClustering을 이용하여 거리는 유클리디안 거리 공식을 사용하였고 cluster 갯수는 300개 최대 10번 시행 중 이전 entropy와 현재 entropy의 차이가 0이면 (완전동일) 한 경우 먼저 멈추게 되는 방식입니다. stop_rate를 변경하면 entropy 오차 범위를 조금 넓힐 수 있으니 유연한 군집이 가능합니다.
초기화 방식은 random sampling이지만 각 중심 벡터가 가능한 균등하게 데이터를 가질 수 있도록 entropy 점수를 매겨 Maximum Entropy를 가지는 중심 벡터로 초기화 하도록 했습니다.
Lion’s Clustering 완성 후에 적는 것으로
참고 자료:
https://roboreport.co.kr/doc2vec-%ED%9B%88%EB%A0%A8-%ED%8C%8C%EB%9D%BC%EB%AF%B8%ED%84%B0-%EC%84%A4%EB%AA%85/
https://lovit.github.io/nlp/representation/2018/03/26/word_doc_embedding/
https://frhyme.github.io/python-libs/gensim1_doc2vec_tagged_document/#taggeddocument-with-multiple-tags
//논문도 넣자