프로메테우스 모니터링 시스템에 대한 연구
프로메테우스는 제가 이해하기 쉽게 적으면 “노드의 메트릭을 수집, 종합하여 저장”해주는 프로그램입니다. 제가 생각하는 프로메테우스는 “수집”과 “종합” 그리고 “저장”을 따로 분리합니다. 그리고 이 포스트도 이러한 구분에 맞추어 내용을 이어나갈 예정입니다.
수집
1 ) 프로메테우스는 서버와 수집기가 왜 분할되어 있는가?
실제로 프로메테우스 서버는 그 자체로 각 Pod나 서버에서 메트릭의 수집을 담당하지 않습니다. 그 이유는 실제로 그렇게 동작을 수행했을 때 발생 할 수 있는 사건을 미리 생각해보면 쉽게 이해 할 수 있습니다.
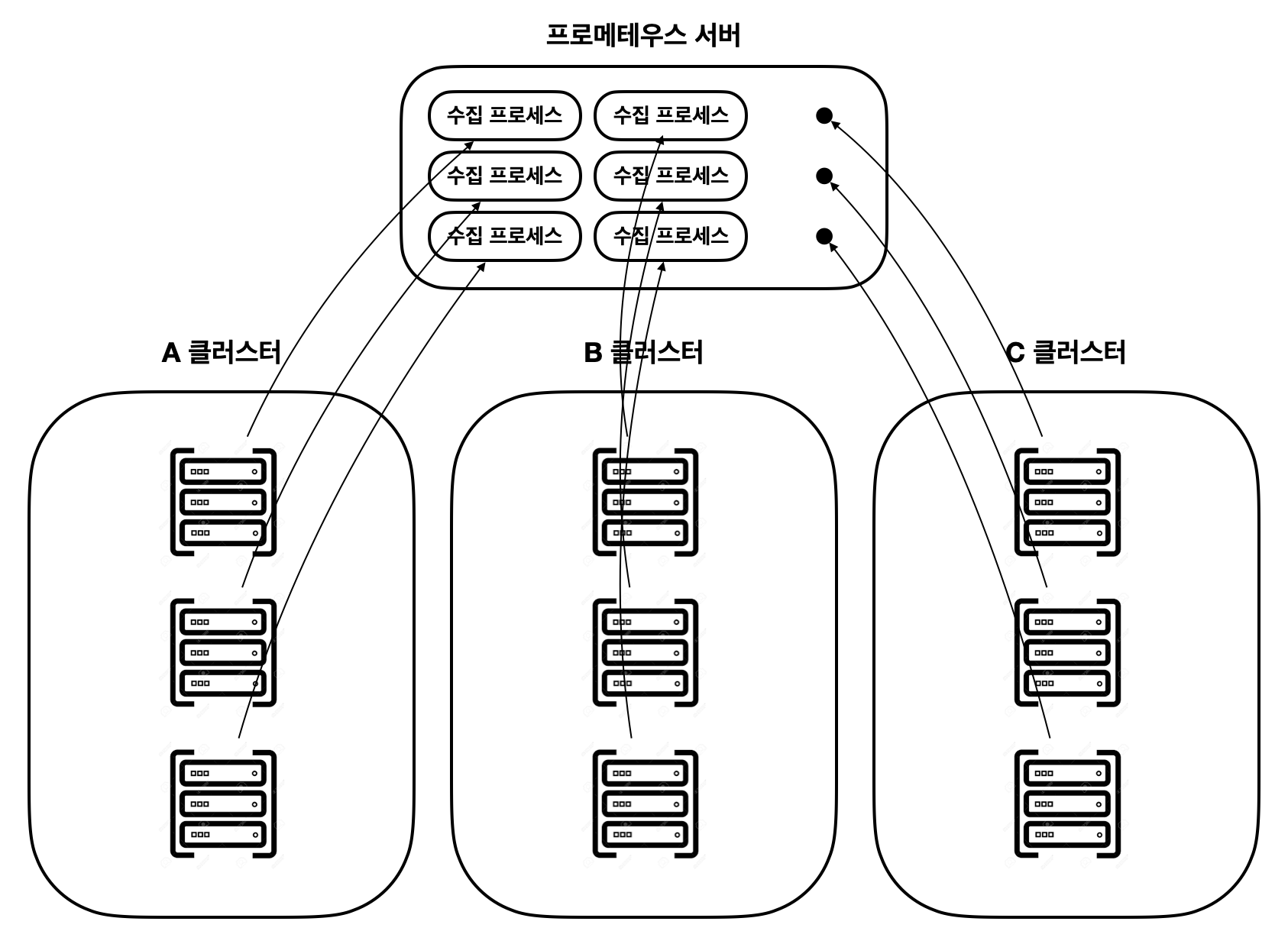
위 그림을 보면 프로메테우스 개별 서버 프로그램 하나에서 다수의 프로세스를 띄우는 것을 볼 수 있습니다. 전문가 분들이 이렇게 구성 할리는 없지만, 만약 구성한다면 이러한 일이 발생하는 이유에 대해서 알아보면 다음과 같습니다.
- 각 노드 별 독립적인 프로세스가 필요하다.
- 메트릭을 수집한다는 것은 결국 컴퓨터의 현재 사용중인 리소스를 관측하는 것이며, 이러한 동작을 수행하는 커널함수는 이미 만들어져 있습니다. 그 의미는 실제 메트릭을 수집하는 방법은 “netstat” 이나 “top” 등의 쉘에서 사용 할 수 있는 명령어의 결과를 정규표현식등을 활용하여 입력받고 있다는 말이 됩니다. 만약 하나의 프로세스에서 관제하는 모든 프로세스에 접근하는 것은 부하 컨트롤 측면에서도 큰 불이익입니다. 물론 다른 리소스에서도 모놀리틱한 부분이 좋아보이지 않습니다.
- 아마 엄청난 리소스가 사용되지 않을까?
- 200대의 노드를 관제하는 프로세스가 한 컴퓨터에 통신하면서, 각 노드는 15초마다 메트릭을 전송한다고 했을때, 많은 메트릭이 쉴틈없이 서버로 입력 될 텐데, 수집은 그렇다고해도 이후 저장하고 쿼리하는 로직이 정상적으로 동작 할 수 있을지 모르겠습니다.
그 외에도 정말 비효율적임은 확실히 알 수 있습니다. 예를들면 서버의 장애가 발생했을 때 어느 노드에서 불안정한 상태가 발생했는지조차 알기 어렵죠.
이러한 이유로 실제로 메트릭을 수집하는 수집기는 따로 존재합니다.
2 ) 수집기는 어떤 일을 하며 구조는 어떻게 구성되어 있는가?
먼저 프로메테우스 동작 프로세스에서 수집에 관련 한 부분을 보면 다음과 같습니다.
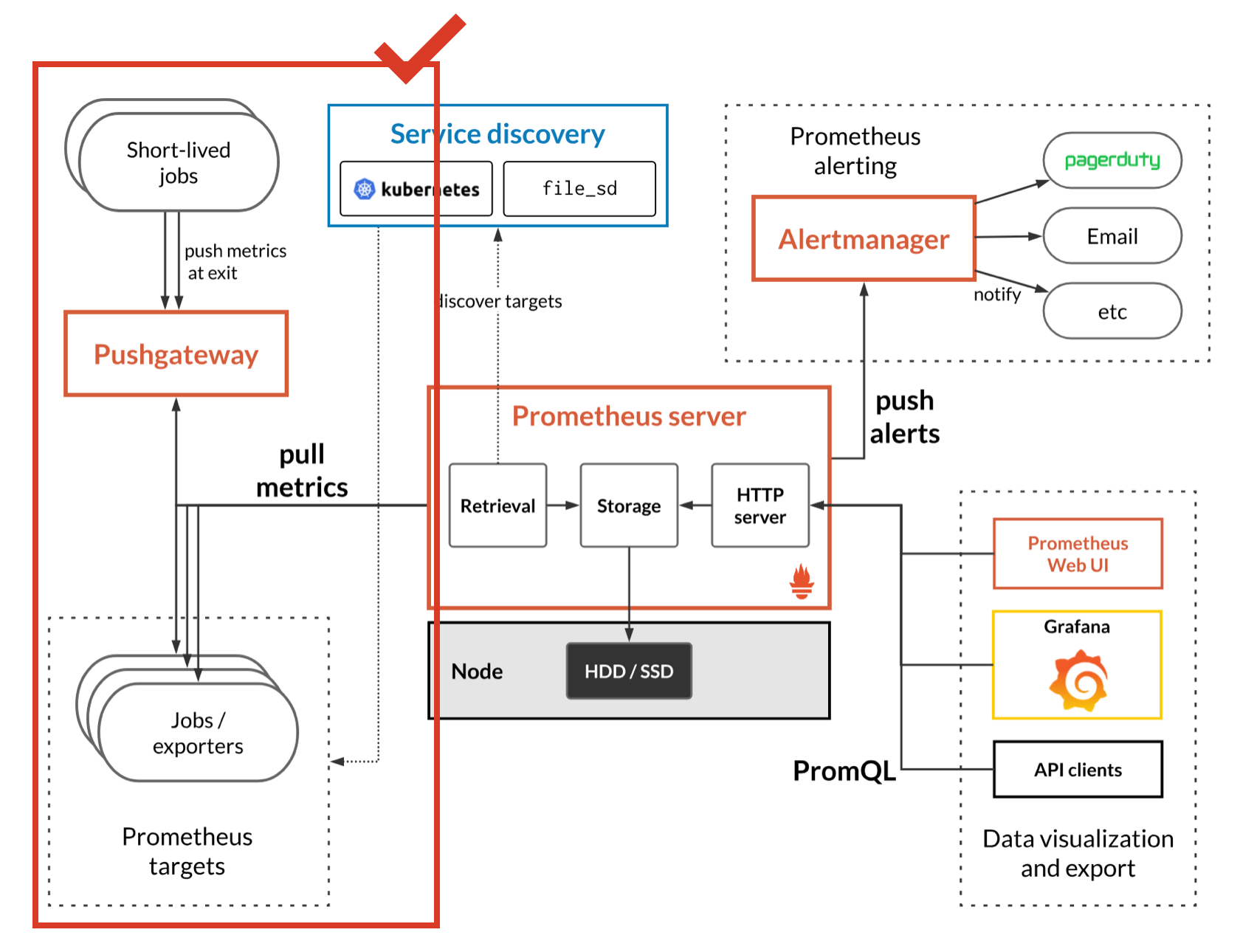
프로메테우스에서 수집기 역할을 하는 것을 “익스포터”라고 합니다. 위 내용에서 알 수 있듯 익스포터는 메트릭을 수집하는 프로세스를 가지고 있으며, 이 프로세스는 담당하는 하나의 노드에 붙어서 쉘 명령어를 통해 원하는 메트릭을 수집합니다. 그리고 수집 된 메트릭을 프로메테우스 서버는 Pull 방식으로 가져갑니다.
이 부분을 나누어서 조금 더 자세하게 알아보겠습니다.
익스포터
익스포터는 다양하게 존재합니다. 노드 자체의 리소스를 파악하기 위한 node-exporter나 데이터베이스의 메트릭을 수집하는 익스포터 kafka와 같은 특정 시스템에 대한 리소스를 파악하기 위한 익스포터 등 다양한 익스포터가 존재합니다.
위 사이트를 보면 지원하는 익스포터의 종류를 알 수 있습니다.
서버에 메트릭을 담는 방법
서버에 메트릭을 저장되는 방법은 Pull와 Push 방법이 있습니다. Pull 방식은 서버가 익스포터에 접근해서 데이터를 가져가는 방식입니다. 이 과정에서 프로메테우스 서버는 익스포터의 논리적 주소(IP)와 포트를 알고 있어야 합니다. 그 외 접근에 필요한 정보가 추가적으로 존재한다면, 그 정보 또한 알고 있어야 합니다. 이러한 설정 값은 프로메테우스 설정 값에 포함되어 있습니다.
특정 익스포터에 대한 정보 ( 접근 관련 정보 포함 )에 이어서 scrape_interval이나 timeout과 같은 설정 값이 있고, 이 간격을 바탕으로 프로메테우스 서버는 주기적으로 익스포터에서 메트릭을 수집합니다.
이 때 등장하는 개념은 “Service Discovery”입니다. 온프레미스 환경에서는 주소가 고정적일 수 있지만, 대체로 클러스터 단위로 관리하거나 혹은 클라우드 환경에서 시스템을 구축하면 특정 서비스가 동작하는 노드의 IP등이 변경되는 일이 발생 할 수 있습니다. 이 때 이러한 정보를 담는 “Service Registry”를 별도로 구축하여 이러한 정보를 추적하는 방식으로 서비스의 IP를 알 수 있도록 합니다.
그러면 프로메테우스 서버는 익스포터 들의 주소를 지속적으로 추적이 가능하게 되고, 동일한 포트를 통하여 HTTP통신으로 수집 한 메트릭을 읽어오면 됩니다.
즉 익스포터가 각각의 대상이 되는 어떠한 시스템에 대한 메트릭을 수집하고 프로메테우스 서버가 그 익스포터에 접근해서 수집 된 메트릭을 통째로 수집하는 방식으로 동작한다고 말할 수 있습니다. 또한 Push 방식도 지원합니다.
Pushgateway라는 별도의 시스템이 존재하고, 익스포터에서 Pushgateway를 통해 지속적으로 서버에 메트릭을 전송하는 방식으로 구축 할 수 있습니다.
수집 과정 확장
일반적으로 데이터베이스 등의 애플리케이션에서의 개념과 비슷합니다. 수직 확장과 수평 확장으로 나눌 수 있습니다.
수직 확장
수직 확장은 말 그대로 인스턴스 혹은 노드 내에서 리소스를 크게 할당하는 방식입니다. 온프레미스에서는 프로메테우스 서버가 많은 리소스를 독점 할 수 있도록 만들거나, 클라우드에서는 인스턴스를 키우고 리소스를 예약하는 등의 방식이 이러한 방식이라고 볼 수 있습니다.
수평 확장
이 부분이 중요한 부분이라고 생각합니다. 흔히 샤딩이라고 불리는 일종의 파티셔닝 방식을 활용합니다.
프로메테우스의 일반적은 수평 확장은 나머지 연산(MOD)를 통해 서버 고유 정보를 해싱하여 해당 샤드로 데이터가 입력되도록 만드는 방식입니다. 이로 인해 여러대의 프로메테우스에 골고루(이상적으로) 분배되고, 그 데이터가 메인 프로메테우스 서버로 전송되어 사용 할 수 있도록 하는 로직입니다. 이러한 방식을 Federation이라고 합니다.
안정성 추가 ( Thanos )
프로메테우스를 수평 확장 했을 때 우리가 얻을 수 있는 이점은 수집하는 메트릭이 클 경우 메모리 사용을 줄일 수 있다는 점입니다. 그런데 이 방식도 결국 하나의 서버에서 동작한다는 점이 있습니다. 즉, 메인 프로메테우스가 죽으면 그 시점에 수집한 메트릭을 얻지 못합니다.
이러한 경우 각 프로메테우스에서 replica와 같은 방식으로 동일한 메트릭을 수집 할 수 있도록 만들 수 있고, 더 나아가 Thanos라는 새로운 서비스를 추가 적용하여 각 프로메테우스의 데이터를 영구 공간 ( S3 등의 )에 저장해놓고 장기간의 데이터를 영구 보관하여 데이터 유실이 없도록 동작시킬 수 있습니다.
저장
프로메테우스는 TSDB(Time-Series DataBase)라는 시계열 데이터를 저장하기에 적합한 저장소에 메트릭을 저장합니다. 모니터링의 특성 상 시간 별 이슈를 파악하기에 가장 적합한 형태라 이러한 방식으로 저장하는 것으로 보입니다.
이번 내용에서는 가장 중점적으로 알아 볼 내용으로는 메트릭이 저장되기까지의 과정과 메트릭이 어떻게 표현되는가에 대한 내용입니다.
메트릭이 어떻게 저장되는가?
메트릭이 실제로 수집되는 시점에서는 기본적으로 Chunk라는 단위로 메모리에 저장됩니다. 그리고 이 Chunk가 일정한 크기, 혹은 어느정도의 시간이 지나면 디스크에 저장됩니다. 그리고 이 과정에서 프로메테우스 서버에 장애가 발생하거나, 재실행등의 문제가 발생 했을 때 메트릭을 유실하지 않게 하기 위해 WAL 파일을 운영합니다. WAL 파일에 로그가 쌓이는 시점은 메모리에 쌓이면서 지속적으로 추가합니다.
메모리에 저장되는 메트릭은 어떤 것이 있는가?
메모리에 쌓이는 메트릭은 Chunk 단위로 현재 쌓여서 모이는 메트릭과 쿼리에 자주 사용되는 메트릭, 제대로 이해하지 못했지만 삭제 대기 중인 메트릭이 있습니다. 실제 현업에서 프로메테우스 서버가 OOM으로 종료되는 사고가 발생 한 적이 있습니다. 이 과정에서 Grafana의 쿼리 기간 단축과 scrape interval을 단축 시켰을 때 메모리가 조금 줄어드는 효과를 본 적이 있습니다.
실제로 프로메테우스 공식 문서에서도 메모리 사용에 대한 문제로 federation을 권장하고 있습니다.
메트릭은 어떻게 표현되는가?
우리가 수집 단계에서 얻은 메트릭은 다음과 같은 형태로 나누어집니다.

일단 timestamp가 있습니다. 우리가 메트릭을 수집 한 시점에 대한 정보가 있어야 시간 단위의 메트릭 검색이 가능하게 됩니다.
그 다음으로는 라벨이 있습니다. 라벨은 이 메트릭에 대한 속성이라고 할 수 있습니다. 어떤 노드에서 입력되었는지, 노드가 가진 특징들이 포함되어 메트릭을 구별 할 수 있는 키정도로 이해하고 있습니다.
예를 들면, 129.42.43.187 주소를 사용하고 있는 클러스터에서 사용하고 있는 CPU만 검색하고 싶다고 했을 때 이러한 주소 값은 라벨에 포함되어 메트릭을 구분 할 수 있는 기준이 되어줍니다.
마지막으로 값이 있습니다. 위에서 든 예시에서는 실제로 사용하고 있는 CPU 리소스 량을 나타냅니다. Health check에서는 True False 와 같은 실제 값을 나타냅니다.
쿼리
가장 정확한 정보는 여기에 있습니다. 프로메테우스 공식 문서 - 데이터 형태
저는 간략하게 요약하여 쿼리를 작성 할 때 고려 할 부분정도만 적어보겠습니다.
Range Vector와 Instant Vector, Scala 값 등에 대한 이해
Instant Vector는 동일한 타임스탬프 기준 각 메트릭의 고유 값입니다. TSDB의 특성 상 시간 기반으로 쿼리를 사용 할 수 있지만, 메트릭 유무를 판단하는 경우에는 굳이 “A시간 ~ B시간 사이의 메트릭”을 쿼리 할 필요는 없습니다. 이 경우에는 해당 메트릭이 수집되는 경우의 마지막 타임스탬프의 하나의 메트릭만 있어도 충분합니다.
Range Vector는 A시점부터 B시점까지의 메트릭을 나타냅니다. 하지만, 주로 Range Vector를 사용하는 용도는 “A시점부터 B시점까지 초당 CPU 사용률의 변화”를 추적하는 등의 모니터링 목적이기 때문에 rate(1초 단위 메트릭 값) 연산을 사용하거나 increase(변화율) 등을 사용하여 모니터링 합니다.
뿐만 아니라 Range Vector는 각종 Aggregation의 대상이 됩니다. Aggregation으로 “특정 라벨의 조건이 일치하는 메트릭만의 값으로 합/나누기/뺴기 등 연산 값”을 얻을 수 있습니다. 그리고 이러한 연산을 수행 할 때 기간 기준을 정하기 위해 [20s] [1m] 등의 기간을 설정 할 수 있습니다.
조인 ( group by와 유사 )
프로메테우스에서 조인은 1:1 조인인지, 1:N 조인인지에 따라 방식이 달라집니다.
1:1 조인
1:1 조인에서는 on과 ignoring을 사용하여 조인을 수행합니다.
- on은 특정 라벨이 같은 값을 조인합니다.
- ignoring은 특정 라벨을 제외한 값들을 조인합니다.
1:N 조인
1:N 조인은 group_left, group_right + on/ignoring 을 사용하여 조인을 수행합니다.
이 경우 양쪽의 메트릭 중 한 쪽은 조건에 적합 한 메트릭이 고유하게 있어야 합니다. 현업에서 로드밸런싱이 수행되면서 조건이 되는 라벨이 중복으로 포함 된 메트릭이 수집되어 해당 지표가 아예 수집되지 않았던 경험이 있습니다.
쿼리의 기간
Grafana등을 사용 할 때 쿼리하는 총 기간을 설정 할 수 있습니다. 이러한 쿼리를 수행 할 때는 너무 긴 기간을 자주 사용하지 않도록 주의해야 합니다.
이전 저장 파트에서 알아봤지만, 쿼리의 대상이 메모리에 적재되기 때문에 과도한 기간 설정은 OOM으로 향하는 길일 수 있습니다.
참고
https://velog.io/@hyunshoon/Monitoring-Prometheus-%EC%B4%9D-%EC%A0%95%EB%A6%AC
https://ssup2.github.io/theory_analysis/Prometheus_Scaling_Federation/