온톨로지 레이어
최근 데이터 분야에서 핫한 키워드인 온톨로지에 대해서 알아보고자 이 글을 작성합니다.
팔란티어라는 회사에서는 현재 데이터 서비스의 새로운 개념을 만들어가고 있습니다. 데이터 수집과 활용에 있어서 현실 세계의 개념을 바탕으로 자동화에 가까운 작업을 수행 할 수 있도록 만드는 방식을 제안합니다. 예를 들어 광고 데이터를 다루고자 할 때 광고의 노출, 클릭 수, 광고의 가치 등이 모두 데이터화 되어 있으면서 서로의 연관성이 명확하면 굳이 광고 캠페인의 성과와 같은 지표를 데이터 분석가가 만들 필요가 있는가? 라는 질문을 던지는겁니다.
이제부터 알아 볼 온톨로지 레이어는 여기서 “광고 캠페인” 데이터와 “광고 노출”의 관계성 등 현실 세계에서 일어나는 일에 대한 관계를 레이어로 표현 한 것을 말합니다. 이것은 서비스 운영을 위한 데이터 구조(우리가 ERD로 표현 할 수 있는 구조)를 덧대어 표현하는 한 겹의 레이어로, 전통적인 데이터베이스에서 사용하는 FK보다 더 나아가 두 데이터의 관계를 직관적으로 명시하는 레이어입니다.
먼저 서비스 운영을 위한 데이터 레이어부터 시작해서 아날로그 데이터의 흐름을 알아 본 뒤 마지막으로 온톨로지 레이어를 직접 설계하는 방향으로 나아가보겠습니다.
서비스 운영을 위한 데이터 레이어
가장 먼저 서비스 운영을 위한 데이터 레이어에 대해 알아 볼 필요가 있습니다. 이 레이어는 우리가 흔히 이해하고 있는 ERD와 같은 구조를 가지고 있습니다. 이 레이어의 테이블 구조를 설계하는 과정에서 중요한 부분은 “원하는 성능을 충분히 만족하는가?” 입니다.
여기서 서비스는 단순히 애플리케이션, 혹은 웹 서비스등을 운영하면서 트랜잭셔널하게 동작하는 데이터베이스 만을 의미하지 않습니다. 데이터 엔지니어에게 이 부분은 이벤트 로그와 그 다음 단계의 실시간/배치 집계 파이프라인이 될 수 있습니다.
어느 방향성이든 목표는 “원하는 성능을 충족하는가?” 입니다. 서비스의 서버에서 트랜잭셔널하게 동작을 원하는 경우에는 이벤트 발생 후 일련의 동작이 지연없이 n 시간 내에 정확한 동작을 수행하는가로 표현 할 수 있고, 데이터 엔지니어에게는 입수 파이프라인에서 데이터의 정합성을 충족하고 분석 및 모델의 입력으로 넣기에 충분한 성능을 낼 수 있는지의 여부 등이 포함됩니다.
예를 들면 다음과 같은 테이블이 있음을 가정해보겠습니다. 각 데이터는 유저가 행동하는 것에 대한 로그 데이터, 몬스터의 액션에 대한 데이터, 아이템 생성 및 관리에 대한 데이터, 인벤토리에 대한 로그 데이터, 변동되는 아이템에 대한 가치를 정제해놓은 데이터 셋, 유저간의 상호작용 데이터입니다.
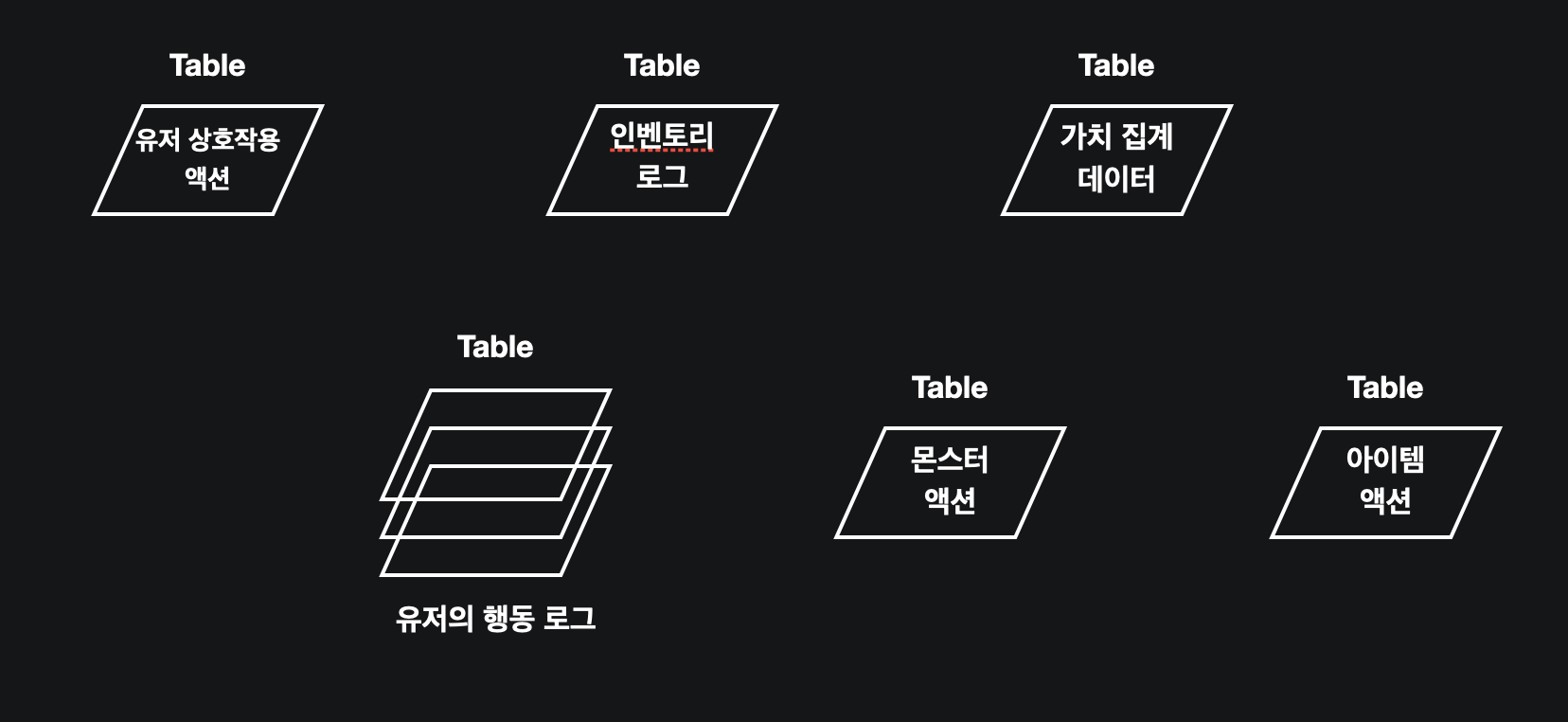
분석가는 이 데이터를 가지고 여러 분석을 수행 할 수 있습니다. 예를 들면 어제 재화를 습득한 유저중에 이상치에 해당하는 가치를 습득한 현금거래, 혹은 부적절한 핵을 사용 한 것으로 예상되는 유저를 추정 할 수 있죠. 서비스 운영을 위한 데이터 레이어는 이렇게 “목적(여기서는 데이터 엔지니어링 관점에서의)을 위한 형태”로 구현됩니다.
아날로그 데이터의 흐름
우리는 유저의 액션을 기반으로 발생하는 하나의 파이프라인에 대해서 알아보고 있습니다. 그러면 유저가 행동을 하면 데이터에는 어떻게 표현되는지 알아보면 데이터를 이해하는 것이 더욱 쉬워집니다.
유저의 동작을 보면 다음과 같습니다.

- 몬스터를 사냥한다.
- 아이템을 습득한다.
- 아이템을 습득하지 않는다.
- 거래를 통해 아이템을 습득한다.
페르소나 방식과 같이 유저의 행동을 기반으로 이벤트를 따라가면 특정 행동에 대해 서비스의 변경 사항을 확인 할 수 있습니다. 여기서 유의 할 점은 서비스에 따라 운영 데이터의 구조는 이러한 흐름을 명확하게 일련의 과정을 따라가지 않을 수 있다는 점입니다. 일단 현재 분석을 하고자 하는 데이터 셋은 단일 유저 액션에 대해서 유기적으로 이어져있다고 가정하고 분석해보겠습니다.
위의 동작을 더욱 세분화 하면 다음과 같습니다.
- 유저가 몬스터를 사냥하는 경우
- 유저가 몬스터를 공격합니다.
- 아이템이 드롭되거나 혹은 드롭되지 않습니다.
- 아이템을 습득합니다.
- 유저가 다른 유저와 상호작용을 합니다.
- 거래를 통해 아이템을 습득합니다.
- 아이템은 매시간 가치가 변동되고 변동되는 아이템의 가치 관련 집계 테이블은 별도로 존재합니다.
더 상세하게 설명 할 수 있지만, 간략하게 위의 내용 정도로만 정리해보겠습니다.
온톨로지 레이어의 주요 사항 중 하나는 “현실 세계의 동작을 반영”하는 것 입니다. 우리가 게임을 하면서 겪는 다양한 행동, 개념적으로 존재하는 하나의 객체는 온톨로지 레이어의 대상이 되고, 우리는 그 관계를 정의 할 수 있습니다. 예를 들면 몬스터는 “유저가 공격할 수 있는 대상”으로 정하고 아이템은 “몬스터를 사냥하면 드롭되는 것”이며, 동시에 “유저간의 거래로 습득 할 수 있는 것”인 관계를 가지고 있습니다.
그러면 이러한 관계를 통한 데이터가 어떻게 표현되는지 알아보면 좋을 것 같습니다.
관계를 통한 데이터 표현
우리는 이러한 관계를 갖는 데이터를 표현하는 방식을 한가지 알고 있습니다. 바로 “그래프 기반 데이터베이스”죠.
그래프 기반 데이터베이스는 다음과 같은 요소로 운영됩니다.
- Node(노드)
- 하나의 객체를 의미한다.
- Edge(엣지 혹은 릴레이션)
- 노드와 노드 간의 연결을 의미하며, 어떤 관계를 가지는지 표현된다.
- Property(속성)
- 노드 혹은 엣지가 어떤 값인지를 나타내는 속성값이다.
이 개념으로 위에서 이야기한 내용 중 “유저”, “몬스터” 그리고 “아이템”을 표현하면 다음과 같은 그림이 그려집니다.
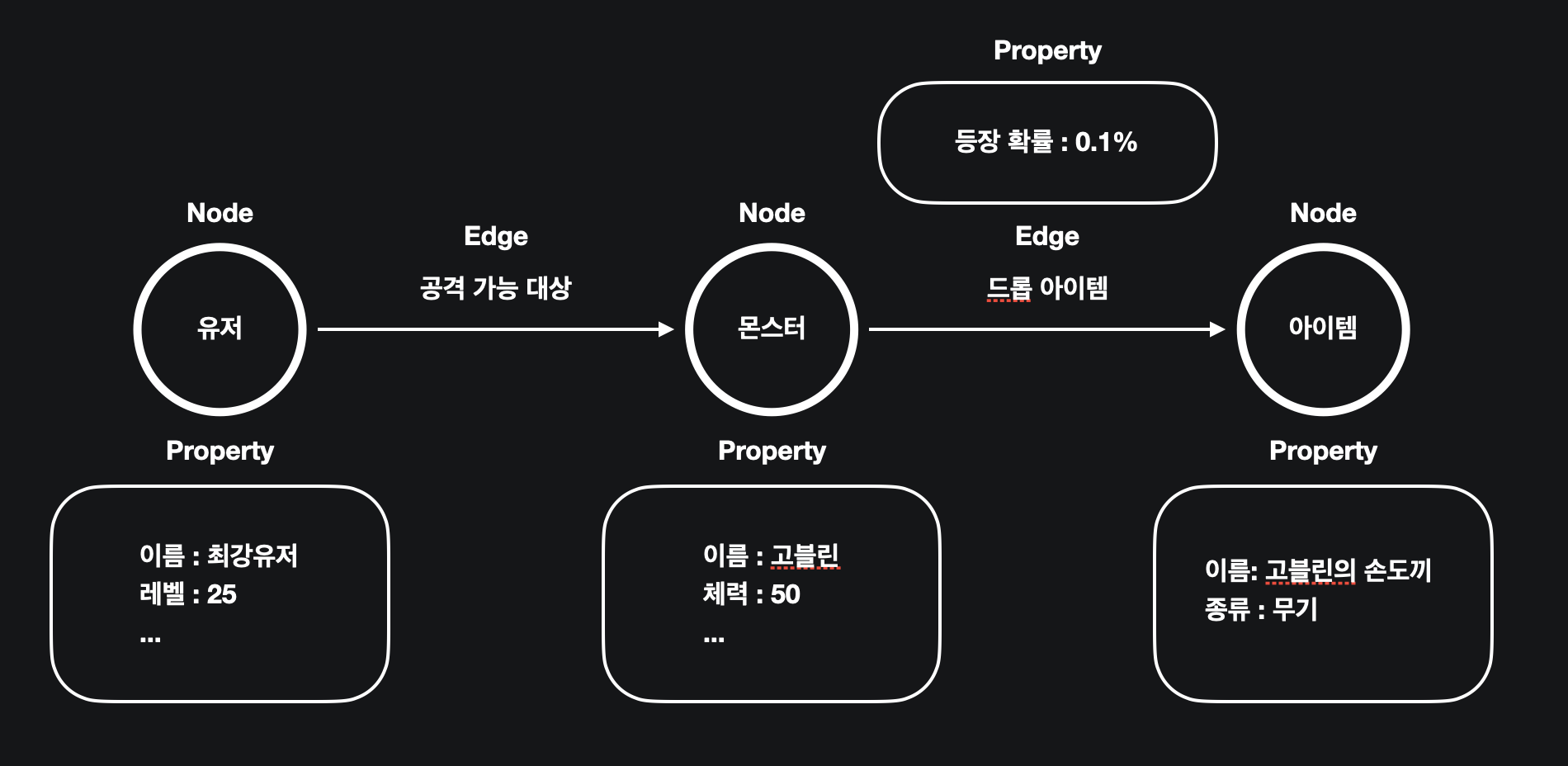
유저는 몬스터를 공격 가능 한 것으로 인식하고, 몬스터는 아이템을 드롭하는 존재로써 위 그래프를 확인하면 최강유저가 고블린의 손도끼를 얻기 위해서는 고블린을 잡을 경우 0.1% 확률로 아이템을 습득 할 수 있음을 알 수 있습니다. 이렇듯 관계를 사용하여 데이터를 표현하면 “연관 정보”를 활용하기 용이하다는 점을 알 수 있습니다.
여기서의 연관 정보는 데이터베이스의 FK와는 다르게 실질적인 값으로 표현되기에 다양한 정보를 내포 할 수 있습니다. “드롭한다”, “공격 가능하다”, “친구이다.” 와 같은 정보처럼 의미를 가진 값으로 표현하기에 활용하기 용이합니다. 하지만 그래프 데이터베이스는 쿼리를 위한 데이터베이스이기 때문에 이런 관계를 사용하는 것에 있어서 한정적인 용도가 있습니다.
예를 들면, 유저와 같은 친구를 팔로워했는지나 같은 페이지를 좋아요를 눌렀는지 등의 단순 관계 쿼리 정도에 사용되는 느낌입니다. 이유는 그래프 데이터베이스도 트랜잭션을 유지하는 하나의 데이터베이스로 서비스에 적용하기 위해서 빠른 쿼리가 필요하기에 그에 따른 관리 방식이 적용되기 때문입니다. 위의 유저와 아이템과의 연결을 지어봐야 실제 게임 분석 단에서 사용 할 일이 없습니다.
하지만 데이터의 관계를 나타내는 것이 불필요한 일은 아닙니다. 오히려 데이터 기반 의사결정을 지향하는 회사에서는 매우 중요한 부분 일 수 있습니다.
온톨로지 레이어
이제 우리는 위에서 알아 본 내용으로 서비스 운영을 위한 데이터 레이어에 아날로그 흐름에 따라 관계를 통해 데이터를 표현해보겠습니다.
서비스 운영을 위한 데이터 레이어를 그대로 가져와서 그림을 그려보면 다음과 같은 그림이 그려집니다.
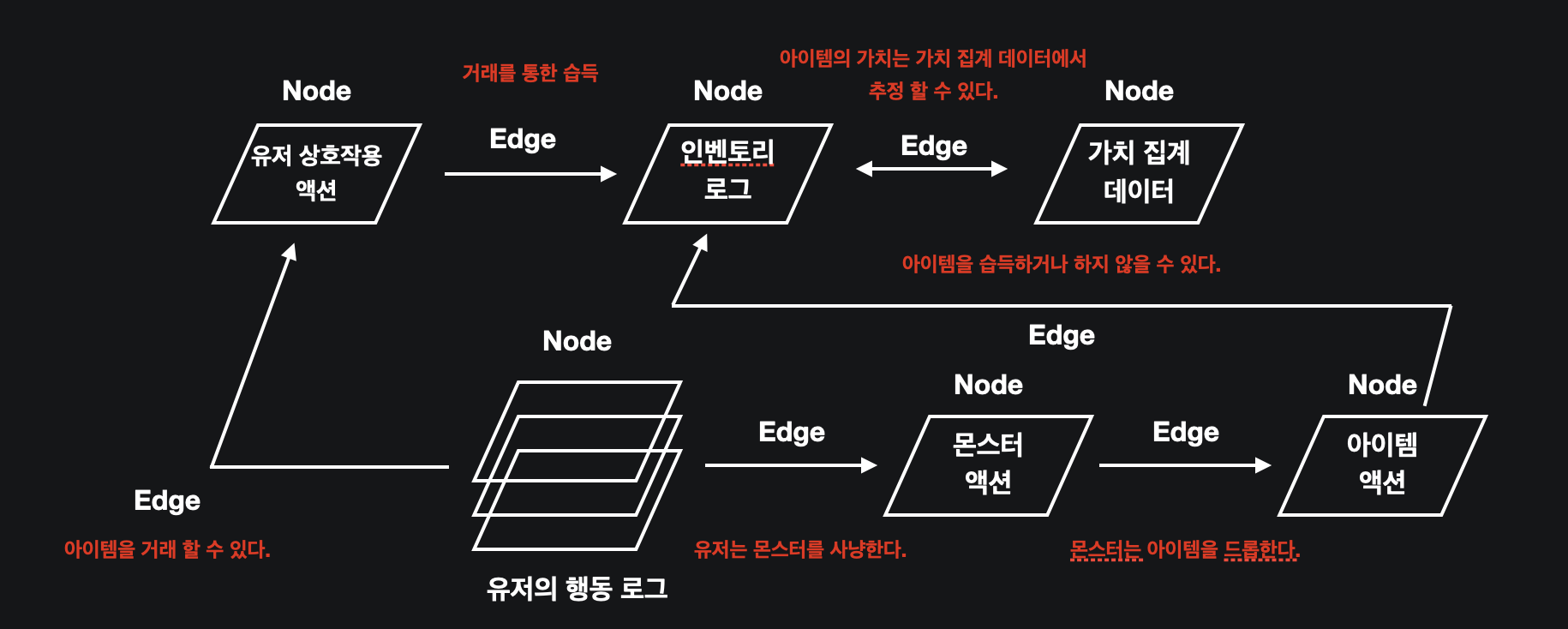
유저의 행동 로그를 시작으로 각 데이터는 관계를 가지고 있습니다. 여기서 관계는 일부러 명사가 아닌 동사 혹은 상황의 발생에 가깝게 텍스트로 서술했습니다. 기존 그래프 기반 데이터베이스에서 A와 B를 연결 할 때 동일 한 명사를 사용 한 건 쿼리의 효율을 높이고, 데이터의 일관성을 유지하기 위함이였으나, 온톨로지 레이어에서는 굳이 그럴 필요가 없습니다. 오히려 LLM을 사용하는 것 처럼 A와 B 데이터의 관계를 서술하는게 활용 시 더욱 효율적일거라 예상됩니다.
여기서 각 노드는 서비스 운영을 위한 데이터 레이어를 설명 할 때 사용 한 테이블을 그대로 가져왔습니다. 각 테이블 혹은 더 나아가 테이블 내부의 컬럼은 그래프 기반 데이터베이스에서 알아 본 하나의 노드가 됩니다.
그리고 각 노드를 연결하는 엣지는 두 노드의 관계를 텍스트 형식으로 적은 하나의 관계입니다. 말했듯이 여기서는 명사가 아닌 관계를 명확하게 적습니다.
프로퍼티는 각 테이블이나 컬럼에 설명으로 적혀있는 정보라고 생각하면 됩니다. 예를 들면 “아이템 액션”이라는 테이블의 설명으로 다음과 같은 정보가 있을 수 있습니다.
- “아이템 액션” : “이 테이블은 다음과 같은 컬럼으로 구성되어 있다. … , 이 테이블은 상태가 고정된 소비재 아이템이 아닌 아이템마다 다른 성능을 가질 가능성이 있는 장비만 포함하고 있으며, property 컬럼에 json으로 속성이 존재하고, 이 값은 생성 후 강화나 여러 요인으로 변경 될 수 있다. 아이템에는 고유 키 값이 있으며 소유자가 변경되는 경우가 있고, A 컬럼이 False면 소유자가 변경 될 수 없다. 그리고 ….”
혹은 컬럼의 설명에도 정보가 표기 될 수 있습니다.
- “아이템 액션 - 소유자” : “이 장비가 인벤토리 혹은 창고에 있거나 장비중인 유저의 고유 ID 값”
하지만 온톨로지 서비스는 하나의 속성값이 더 추가됩니다. 그 값은 “액션”으로 어떤 데이터가 변경 될 수 있는 원인을 정의해두는 방식입니다. 여기서의 예시는 바로 “아이템의 가치 메타 테이블”을 들 수 있습니다. 우리는 공급이 많을수록, 수요가 많을 수록 그 아이템의 가치가 변경된다고 생각합니다. 물론 그 규칙이 완전하지 않지만, 일단 공급이 많으면 아이템의 가치에 영향을 미칠 수 있음을 쉽게 예상 할 수 있습니다.
그러면 다음과 같은 액션을 추가해보죠.
- “아이템의 가치 메타는 아이템의 공급/수요로 변경될 수 있다.”
이렇게 우리는 하나의 온톨로지 레이어에 대한 설계를 진행 할 수 있습니다.
어떻게 사용 할 수 있을까
데이터 기반 의사결정을 지향하는 회사에서의 데이터 민주화를 구축하는 방향의 마지막 단계는 자사 데이터 기준 자연어로 쿼리를 생성하는 것이라고 생각하는 편입니다. 복잡한 조건이 가능 할 수록 회사는 데이터를 자산화하는 과정에서 높은 성과를 얻었다고 생각하기 때문입니다.
온톨로지 레이어를 가지고 있다면 이러한 쿼리 생성에서 더욱 좋은 효과를 얻을 수 있습니다. 다양한 데이터 셋에서 필요한 컬럼을 탐색하고, 데이터를 조합하여 결과를 내야하는 상황에서는 단일 테이블 및 컬럼의 설명 외에도 다양한 정보가 필요하기 때문입니다. 그리고 이러한 쿼리 생성을 자동화 할 수 있다면 파이프라인 자체를 자동화하는 것도 불가능하지 않습니다.
실제로 hive 혹은 glue등의 외부 카탈로그를 적용하여 데이터를 탐색하게 되면서 데이터의 스키마, 표현 방식이 규격화되어 데이터를 자산화하는 것이 쉬워졌기 때문에 파이프라인도 단순화되고 있는게 현재 시점의 데이터 엔지니어링입니다.
그러면 우리가 만든 온톨로지 레이어에 임의의 데이터를 넣고 가볍게 활용해보겠습니다. 실제 데이터를 넣기에는 너무 길어질 수 있으며 시각적으로 불편 할 가능성이 있기 때문에 간략하게 적겠습니다.
1-1. "최강유저"가 "고블린"을 쓰러뜨렸다.
1-2. "고블린"은 "고블린의 도끼"를 드롭했다.
1-3. "최강유저"가 "고블린의 도끼"를 습득했다.
1-4. "고블린의 도끼"는 1,000원의 가치를 지닌다.
1-5. "고블린의 도끼"가 더 흔해졌으므로 예상 가치는 999원으로 줄어든다.
2-1. "치트유저"가 "고블린"을 쓰러뜨렸다.
2-2. "고블린"은 "왕의검"을 드롭했다.
2-3. "치트유저"가 "왕의검"을 습득했다.
2-4. "왕의검"은 5,000,000원의 가치를 가진다.
2-5. "왕의검"이 더 흔해졌으므로 예상 가치가 4,975,000원으로 줄어든다.
이러한 로그 정보가 있을 때 우리는 이전에 설정한 온톨로지 레이어가 각 데이터(테이블 혹은 컬럼)에 포함되어 있으니, 이 정보를 기반으로 쿼리를 만들어 볼 수 있습니다.
질문 : 고블린을 사냥 했을 때 원래는 드롭되지 않는 아이템이 드롭 된 로그를 얻는 쿼리 알려줘. 어떤 유저가 습득했는지도 알려줘.
답변 : 몬스터와 아이템 테이블의 관계는 "몬스터가 사냥 되었을 때 드롭 하는 것"이므로 몬스터의 드롭 아이템과 관련한 컬럼을 탐색 후 explode 한 뒤 아이템 테이블과 조인을 진행합니다. 드롭되지 않는 조건이므로 outer 조인 시 몬스터 컬럼의 정보가 비어있는 경우를 찾습니다. 유저 정보를 원했으니 로그에 남은 유저의 ID를 기반으로 유저 메타와 조인합니다.
SELECT userid, monsterid, itemid, itemname
from
(
SELECT monsterid, explode(items) as itemid
FROM monster
) as m1
right outer join item
on m1.itemid = item.itemid
where item.monsterid is null
....
이렇듯 온톨로지 레이어는 우리가 정의한 테이블의 설명이나 구조를 넘어서 현실의 정보를 하나의 레이어로 쌓아 사용자가 직관적으로 이해 할 수 있고 활용 할 수 있는 중간 계층이 되어 줄 수 있습니다. 팔란티어라는 회사를 거치지 않더라도, 데이터를 표현하는 하나의 계층에 대한 개념은 추후 데이터 카탈로그 및 거버넌스에서도 이러한 계층이 유용하게 사용 될 것 같습니다.