빅데이터 처리 아키텍처
데이터 엔지니어의 꿈을 가지고 공부를 했지만 아직까지 제대로 설계 된 데이터 처리 아키텍처를 가진 회사에서 일 한 적이 없기 때문에 잘 모르고 있었던 대표적인 아키텍처를 알아보도록 하겠습니다.
아키텍처에 대해 알아보기 전에 우리가 알아야 할 데이터의 특징이 있습니다. 그건 바로 배치 처리와 실시간(스트리밍) 처리입니다. 이 부분부터 공부를 하고 제대로 아키텍처를 논하도록 합시다.
데이터 처리는 어떻게 수행하는가?
데이터 처리는 “데이터 처리는 데이터를 정보나 지식으로 바꾸는 컴퓨터 처리를 두루 가리키는 용어”라는 다소 넓은 또 모호한 문장으로 위키에 올라와있지만, 데이터 엔지니어 입장에서는 ETL의 Transform이라고 생각해 볼 수 있을 것 같습니다.
이 부분에서는 최근에 관심을 가지고 있는 로그를 바탕으로 예시를 들어 보겠습니다. 예를 들면 다음과 같은 로그 셋을 얻었다고 가정해보겠습니다.
GET {source_ip} /purchase/{ID}/list?itembox=1&minprice=20&since=20220830-123542 HTTP/1.1
예시로 만든 access_log로 A라는 사용자는 구매한 물건 목록중에서 가격이 20달러 이상이고, 8월 30일 12시 35분 42초 이후에 구매한 물건을 찾고 있습니다.
서비스 레벨은 직접적인 요청에 대한 응답을 빠른 시간에 제공해주어야 합니다. 하지만 데이터를 수집하는 단계에서는 무조건 그렇게 클라이언트의 요청을 즉각적으로 수집 할 필요는 없을 수 있습니다.
예를 들면 마케팅 전략에 대한 평가를 하고 싶은데 이러한 정보는 N시간에 대한 결과 ( 예를 들면 3시간 내에 A/B 테스트의 유저 액션 )만을 확인하면 됩니다. 물론 실시간으로 보고싶을 수 있지만요.
그런 경우에는 우리는 일정 시간 혹은 어느 정도의 양을 모아서 처리하는 방향을 생각 할 수 있습니다.
이렇게 일정 수준의 데이터를 모아서 처리하는 방식을 배치 처리 그리고 실시간으로 데이터를 처리하는 방식을 스트리밍 처리라고 합니다.
1. 배치 처리
배치 처리는 설명 한 것 처럼 일정 수준의 데이터를 모아서 처리하는 방식 입니다. 그러면 이렇게 데이터를 묶어서 처리하면 어떤 점이 좋은가를 알아봅시다.
- 1. 첫 번째로 데이터를 재입력하기 쉬운 프로세스입니다.
한 번에 처리하는 데이터는 기본적으로 특정 한 조건 ( 특정 조건으로 묶인 쿼리, 특정 이름으로 저장 된 파일 )로 표현되어 있습니다. 이 경우 이후의 데이터 처리에 실패했을 때 동일한 데이터 셋을 다음 로직으로 보내는데 용이합니다.
- 2. 두 번째로 무거운 처리 혹은 대량의 데이터를 처리하는데 용이합니다.
특히 요즘 DL을 이용한 모델을 학습하는데에 있어서 대량의 데이터가 동시에 입력이 되어야 하는 조건이 있습니다. ML은 기존의 파라미터를 가진 채로 추가적인 학습을 할 수 있지만, 그렇지 못할 경우는 대량의 데이터 셋을 통째로 학습하는 프로세스가 필요하죠. 이 경우 배치 처리가 사용되어야 합니다.
마찬가지로 대량의 데이터는 배치 처리가 적합한 경우가 많습니다. 일반적으로 어떠한 처리를 할 때 한 번에 ( 물론 처리 할 수 있는 양 내에서 ) 많은 데이터를 처리하는게 개별 처리하는 것 보다 나은 것은 하드웨어 적인 측면에서도 세션연결이나 여러 면에서도 유리 한 것은 명확합니다.
2. 스트림 처리
스트림 처리는 실시간으로 데이터를 처리하는 방식입니다. 사실 스트림 처리를 들으면 이런 생각을 할 수 있습니다.
“그냥 다 스트림 처리하면 되는 거 아니야?”
어떤 데이터든 실시간으로 처리를 하게 된다면, 데이터 분석가들도 항상 실시간으로 데이터를 분석 할 수도 있고 ML/DL 또한 일정 시간에 대한 최대한의 데이터를 가지고 모델링을 할 수 있게 됩니다.
“진짜 스트림 처리가 최고 인가?”
하지만 그렇지 않을 수 있습니다.
처리하는 서버에 문제가 생기면 실시간으로 발생하는 데이터에 대해서는 재입력을 하지 못하게 됩니다. 왜냐하면, 별도로 데이터를 수집한 형태가 아니기 때문에 디스크에 저장되어 있지 않는 형태이고, 처리중인 데이터가 저장되어 있지 않기 때문에 결국 데이터 유실이 발생하게 됩니다.
이러한 스트림 처리를 바로 at_most_once를 보장한다고 합니다. 최대한 1번 전송하는 방식이죠.
물론 이런 문제는 예전의 스트림 처리에 대한 문제입니다.
컴퓨팅 파워에 대한 발전과 새로운 로직의 개발로 스트림 처리를 더욱 안정적으로 수행하기 위한 방법론이 나오면서 이러한 문제는 어느정도 해결됩니다.
바로 Kafka와 같은 메시지 브로커의 등장입니다.
데이터를 처리하기 전에 우리는 처리하기 전의 데이터인 Kafka에 큐 형태로 데이터를 넣고, 실시간으로 그 데이터를 꺼내서 사용 할 수 있습니다. 기본적으로 데이터를 복제해놓는 특성을 가지고 있기 때문에 설정한 시간내에는 해당 데이터를 재입력 할 수 있습니다.
Kafka는 현재는 at_least_once ( 적어도 1번 )와 exactly_once ( 진짜 1번만 )을 지원한다고 합니다.
“와 그러면 진짜 스트림 처리가 최고네!”
꼭 그렇지 않습니다!
중요한 점은 스트림 처리는 부하를 항상 가지고 있다는 점을 알아야합니다. 즉 재입력을 할 때는 기존의 부하에 재입력에 대한 부하까지 감안해야 하는 말이죠. 서버도 상시 부하에 대해서 민감하게 설계되어야 합니다.
Architecture
가장 대중적인 아키텍처인 Lambda 아키텍처와 스트리밍 데이터 처리가 안정성이 높아진 현재 각광받고 있는 Kappa 아키텍처에 대해서 알아보도록 하겠습니다.
1. Lambda Architecture
Lambda Architecture은 가장 대중적으로 사용되는 데이터 처리 아키텍처입니다. 여기서 주목하는 점은 실시간 처리는 안정적이지 않지만 빨리 결과를 볼 수 있다는 점 그리고 배치 처리는 안정적이지만, 즉각적인 데이터를 볼 수 없다는 점입니다.
그래서 결국 “둘 다 쓰자!”로 서로의 문제를 해결하고자 합니다.
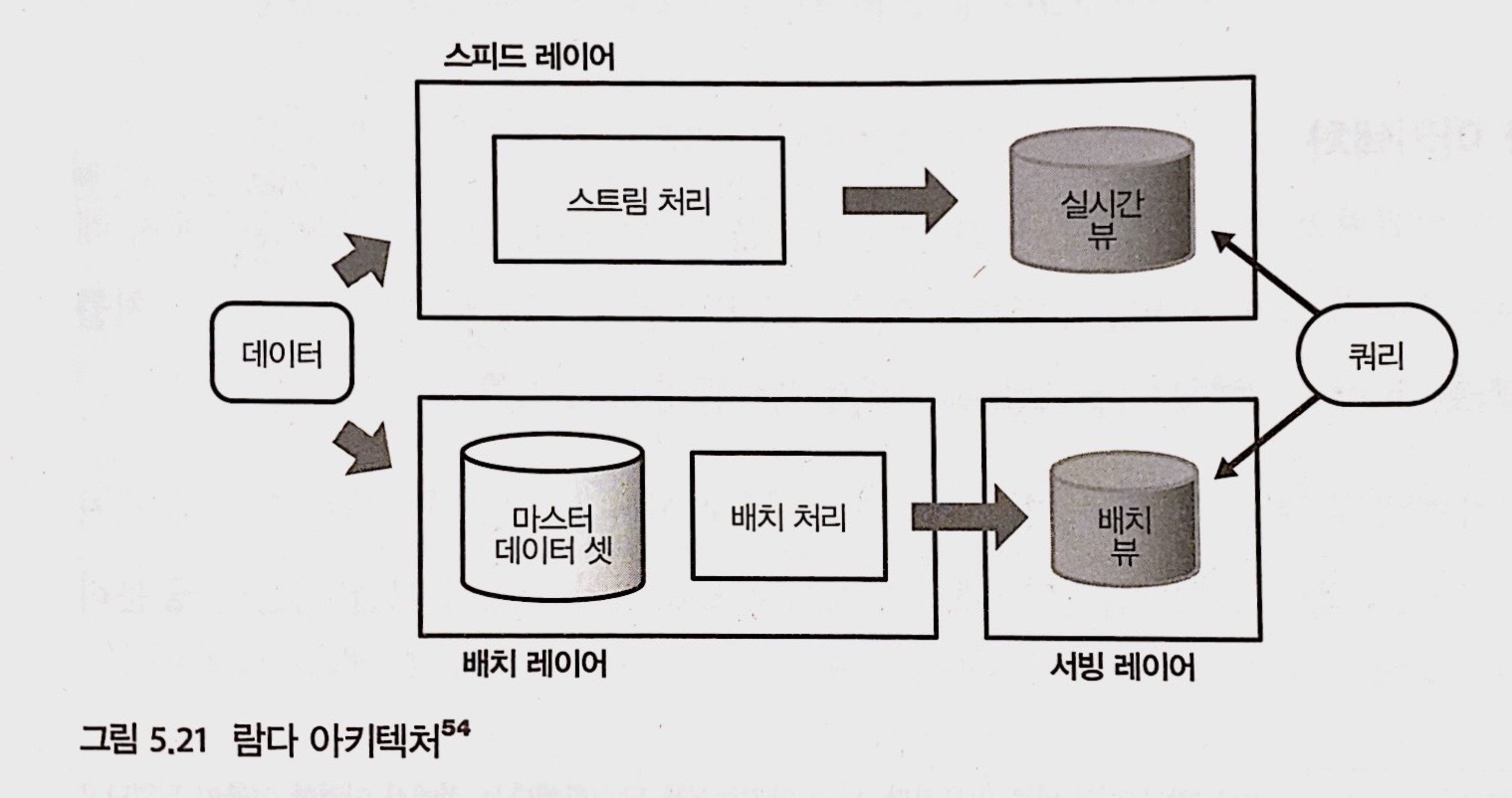
위의 그림이 Lambda Architecture의 설계 방법입니다. 총 3개의 레이어로 이루어져 있는데, 이제 각 레이어에 대해 특징을 알아보겠습니다.
1.1 배치 레이어
1. 배치 레이어는 모든 데이터를 처리하는 레이어입니다.
2. 과거의 데이터를 장기간 저장하기 때문에 언제든 원하는 정보를 찾아 볼 수 있습니다.
3. 일반적으로 대용량의 데이터를 1회 처리하는 방식이라 오랜 시간이 걸립니다.
이러한 특징으로 인해 배치 처리에 대한 장점을 가지고 있을 수 있습니다. 다소 대용량의 데이터를 효과적으로 처리 할 수 있으며 재입력 또한 가능합니다.
1.2 스피드 레이어
1. 스트림 처리를 수행하는 레아어입니다.
2. 데이터 보관 기간을 짧게 설정해서 배치 레이어와 중복성을 제거합니다.
보통 스피드 레이어를 사용 한 후의 데이터는 빠른 의사결정에 활용 할 수 있습니다.
A/B 테스트의 결과를 당장 오늘 알아보고 싶을 경우, 모든 유저의 access_log를 배치 처리로 얻어내기에는 긴 시간이 소요되기 때문에 실시간인 스피드 레이어의 뷰를 통해 어느정도의 경향 정도를 확인하는 경우가 예시라고 볼 수 있습니다.
문제는 어느 정도의 경향 정도의 완벽하지 않은 데이터 셋이라는 점입니다. 처리속도 및 처리 량의 문제이든 어느정도 완벽하지 않음을 가정한 처리라는 점을 이해해야 합니다.
1.3 서빙 레이어
1. 배치 처리의 결과와 실시간 처리의 결과의 뷰를 서빙 레이어를 통해 접근 합니다.
이 부분은 조금 알아보고 있지만, 결국 배치 처리와 스트림 처리로 얻은 데이터를 합쳐서 보기 위한 레이어라고 할 수 있을 것 같습니다.
배치 레이어와 스피드 레이어를 합치면 다음의 문제를 확인 할 수 있겠네요.
- A/B 테스트를 3일 간 수행했는데 실 서비스에 반영 할 지 오늘 선택하자!
- 배치 레이어는 로그를 3시간 간격으로 배치 처리하여 저장소에 담는다.
- 스피드 레이어의 삭제 기간은 1일이다.
A/B 테스트에 대한 분석 로그는 배치 레이어 ( 최대 2일 21시간 ) + 스피드 레이어 ( 최대 최근 3시간 )간의 데이터를 합치면 대략적인 3일간의 A/B 테스트의 결과를 얻을 수 있다.
제가 보기에는 이러한 Lambda Architecture가 최선인 것 같지만 문제점은 있다고 합니다.
1.4 Lambda Architecture 의 문제점
가장 큰 문제는 독립 된 두 버전의 파이프라인이 필요하다는 점입니다. 데이터 엔지니어는 두 버전 모두 개발해야하고, 운영또한 두 버전 모두 신경써야 합니다.
또 다른 문제는 두 파이프라인을 통해 나온 데이터를 통합해서 사용해야 합니다. 즉 이 부분에서 복잡성이 늘어나고 어느정도의 성능에도 영향을 주게 됩니다.
Kappa Architecture
“그러면 둘 중 하나만을 사용하면 안될까요?”
가능합니다. 물론 배치 처리가 스트림 처리를 대신 할 수는 없기 때문에 우리는 스트림 처리로 배치 처리를 대신 하는 방향으로는 해결 할 수 있습니다.
그러기 위해서는 스트림 처리의 안정성을 높이는 방안을 마련해야 합니다.
여기서 아까전에 말했던 Kafka와 같은 메시지 브로커를 이용하는 방안이 등장합니다.
Kafka의 데이터 보존 기간을 늘려서 배치 처리와 마찬가지로 재입력에 용이하게 설계할 수 있습니다. 뿐만 아니라 at_least_once 이상을 보장하는 형태로 설계하게 되면 데이터가 누락되지 않도록 할 수 있습니다.
이로 인해 스트림 처리 만으로 배치 처리를 대신하게 되는 것이 바로 Kappa Architecture입니다. 실제로 이 방향으로 많은 회사들이 변경하고자 한다는 것을 들었습니다.
Kappa Architecture 의 문제점
Kappa Architecture의 문제점은 거의 성능에 관련 한 부분이 많습니다.
기본적으로 스트림 처리를 안정적으로 전달받기 위해 Kafka와 같은 브로커를 이용하고, 이러한 부분이 트랜잭션과 비슷한 역할을 하기 때문에 실시간 처리에 대한 부하가 높습니다.
재입력을 할 때는 스트림 처리를 위한 큰 부하를 가진 상태에서 추가적으로 재입력을 수행하기 때문에 부하에 더 큰 부하를 받게 되는 점도 있습니다.
스트림 처리라는 점으로 인해 DL에서 학습 할 때 작업이 어려 울 수 있습니다.
하지만 대부분의 단점은 분산 처리와 scale-out, 클라우드 컴퓨팅으로 해결이 가능하다고 합니다. 결국 돈이네요.