이 글은 Martin Kleppmann의 데이터 중심 애플리케이션 설계를 읽고 기억하고자 적는 게시글입니다.
3. 저장소와 검색
세상에서 가장 간단한 형태의 데이터베이스는 바로 파일의 끝에 값을 쓰는 방식의 파일 구조입니다. shell script에서 특정 라인의 값을 파일에 추가하는 » 명령 정도가 예라고 생각 할 수 있죠.
#!/bin/bash
db_set(){
echo "$1,$2" >> database
}
db_get(){
grep "^$1," database | sed -d "s/^$1,//" || tail -n 1
}
위의 bash script는 bash의 매개변수로 주어진 첫번째 값을 키로 두번째 값을 값으로 설정하여 데이터베이스( 예시는 파일 )에 저장하고 그 값 중 마지막을 읽어오는 방식으로 동작하는 데이터베이스입니다.
이 코드는 매우 빠르게 동작합니다만, 문제는 db_get()의 효율입니다. 여기서의 database가 파일일 경우에는 tail을 먼저 수행해서 효율적일 수 있지만, 만약 n번째가 내가 찾는 값이라면 어떨까요?
문제는 질의입니다. 어떠한 조건을 통해 원하는 값을 찾을 때 이러한 파일이라면 모든 값을 읽으면서 그 조건에 맞는 값을 돌려주어야 하기 때문에 시간복잡도는 약 O(n)이 소요됩니다.
그러면 이러한 문제를 데이터베이스는 어떻게 해결했을까요? 그건 우리가 자주 사용하고, 고려하고 있는 인덱스(색인) 입니다.
인덱스를 이해하는 기본 바탕은 바로 추가적인 메타데이터의 생성입니다. 그리고 이러한 메타데이터는 원하는 데이터를 찾을 수 있도록 이정표와 같은 역할을 수행해줍니다.
언젠가 면접 질문으로 이런 질문을 받은 경험이 있습니다.
“데이터베이스의 용량이 무제한 일 때 모든 컬럼을 인덱스를 설정하면 안되나요?”
그때 이전의 대답이 “인덱스는 별도의 메타데이터이기 때문에 추가적인 용량이 사용됩니다.” 였기 때문에 이 질문에 대한 대답에서 막혔던 기억이 있습니다. 그리고 지금 이 책을 읽으면서 대답 할 수 있습니다.
“마찬가지로 메타데이터이기 때문에 쓰기의 효율이 낮아집니다. 크기가 고정적이고, 서비스 상 빠른 검색이 필요하다면 조건적으로 좋을지 모르지만, 입력이 많은 경우 좋지 않은 선택인 것 같습니다” 라고요. 이걸 그때 알았어야 했는데, 아쉽습니다.
아무튼 이제 인덱스의 가장 대표적인 형태인 로그 구조 계열의 저장소 엔진과 페이지 지향(B-Tree) 계열의 저장소 엔진을 알아보고 RDB와 NoSQL의 저장소 엔진에 대해서 알아보겠습니다.
여기서 로그란 추가 전용 레코드 입니다. 이에 대한 설명은 차차 나올 것 같습니다.
1. 해시 색인
키 - 값 색인
키와 값을 이용한 색인은 파이썬의 Dictionary 형태와 유사합니다. 특정 키가 있고, 그 키로 접근했을 경우 원하는 값이 있는 형태죠. 해시테이블 방식의 데이터 접근 방식이라고 생각하면 될 것 같습니다.
해시 색인은 기본적으로 범위 연산을 가정하지 않습니다. 그저 특정한 어느 값에 대한 데이터를 빠르게 찾기 위해 고안되었으며, 예를들면 로그인 서비스에서 아이디를 찾을 때 고유한 아이디 1개를 찾기 위해 전체 데이터를 읽기보다 그 아이디의 해시값을 찾아가면 더욱 빨리 접근 할 수 있듯이 말이죠.
가장 처음으로 나온 방식은 키를 데이터 파일의 바이트 오프셋 ( 바이트 단위로 데이터의 시작 지점에서 얼마나 멀리 떨어져 있는가 )를 이용 한 인메모리 데이터 저장 방식을 보여줍니다. 이 방식은 듣기만해도 매우 빠른 저장 방식임에는 확실합니다.
왜냐하면 적을 메타 데이터가 쓰는 데이터의 바이트 기준 시작지점 - 데이터 파일의 메모리 시작 지점이라 매우 빠를 것이 당연합니다.
모든 데이터는 인메모리이기 때문에 적재하는 데이터의 양이 작지만, 빠른 읽기 쓰기를 보장합니다. 이러한 방식을 사용한 저장소 방식은 비트캐스트가 있다고 하는데, 이 방식은 키의 값이 자주 바뀌는 상황에서 좋다고 합니다. 하긴 메모리 내에서 특정한 키에 해당하는 값을 변경 할 때 매우 효과적인 것 같습니다.
하지만 중요한 건 인메모리의 한계인 장애입니다. 우리가 데이터베이스를 사용하는 이유 중 하나는 데이터의 영구성, 즉 디스크에 저장함으로써 서버에 장애가 생겨도 유지되는 특성 때문이죠.
비트캐스트는 로그 구조 계열의 저장소 엔진입니다. 따라서 추가 전용 레코드인데, 결국 파일의 쓰기만을 수행하고 삭제하거나 탐색하지 않는 방식의 로그입니다. 비트캐스트의 경우 삭제를 할 때 툼스톤이라는 레이블이 담긴 레코드를 추가함으로써 이전 쓰기 내용을 무시하도록 한다고 합니다.
그러면 비트캐스트의 로그는 용량이 무한인가요? 라는 질문이 나올 수 있습니다. 말그대로 계속 쓰기만 하니까요.
그걸 방지하는 방법은 바로 세그먼트 컴팩트입니다. 간단히 말하면, 추가 전용 레코드에 담긴 데이터들을 파일을 구분하여 이전 로그, 이후 로그 형태로 나눈 뒤 이후 로그는 지속해서 변경 내용을 추가하고 두 로그 파일을 읽어들여 각 키의 가장 최근 값으로 수정하여 저장해 놓는 로그 기법을 말합니다. 그러면 장애가 일어나서 서버가 재부팅 되어도, 로그에 남은 파일을 기반으로 회복 할 수 있으며, 로그 파일의 크기가 무한대로 확장되지도 않습니다.
이 방식의 문제점을 몇 가지 말하고, 그에 대한 대안등을 말했는데 요약하면 다음과 같다.
- csv는 로그에 적합한 형식이 아니므로 바이트 단위 문자열 길이를 부호화한 뒤 원시 문자열을 부호화 하는 바이너리 형태로 사용해보자.
- 레코드 삭제는 툼스톤을 사용한다.
- 고장 복구 시 전체 세그먼트 파일을 처음부터 끝까지 읽고 복원 할 수 있으나, 이 경우 오랜 시간이 걸릴 수 있어 서비스에 위험이 될 수 있다. 스냅샷을 저장해라
- 비트캐스트의 체크섬으로 로그 저장 과정에 문제를 해결해라
- 데이터 파일 세그먼트는 추가 전용 혹은 불변이므로 스레드로 다중 읽기가 가능하다. 하지만 쓰기는 1개의 쓰기 스레드를 사용하는게 안전하다.
하지만 해결하지 못하는 근본적인 문제도 있습니다.
- 해시 테이블의 키가 너무 많은 경우 문제가 된다. 그 경우 무작위 접근 IO가 많이 발생하고, 해시 충돌을 위한 비용이 크기 때문에 좋은 성능을 기대하기 어렵다.
- 해시 테이블의 범위 질의는 효율적이지 않다. 결국 모든 키는 개별 조회한다.
SS 테이블과 LSM 트리
위의 가장 기본적인 형태의 인메모리 키-값 색인에서 더욱 발전한 형태가 있습니다. SS 테이블을 유지해서 검색하는 방법이 바로 그겁니다.
기본적인 키-값 색인은 키가 많아 질 경우 키를 탐색하는데 오래 걸린다. 는 문제가 있었습니다. 컴팩션을 통해서 모든 키가 유일함이 보장 되더라도 결국 키가 많으면 탐색하는데에 시간이 소요되는건 마찬가지죠. 이러한 점은 SS 테이블에서 어느정도 해결이 가능합니다.
아래의 그림은 간단한 형태의 SS 테이블입니다.
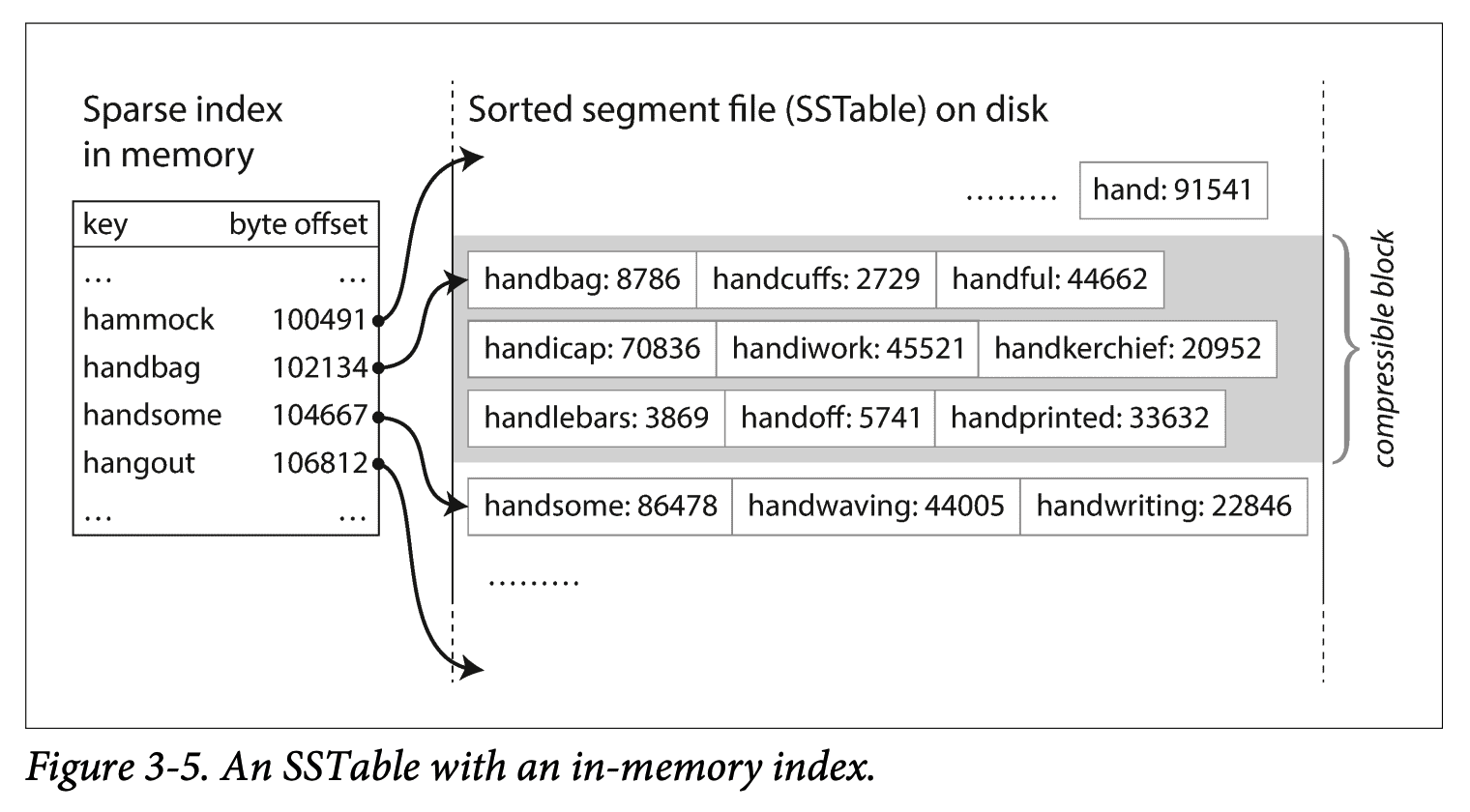
기존에는 모든 키를 색인으로 저장하여 해당 값을 탐색하기 위해서 모든 키에 접근했습니다. 메모리 상 효율이 좋지 않은 랜덤 엑세스 방식으로 말이죠.
하지만 컴팩션을 수행 한 후 값을 정렬하면 문제는 쉬워집니다. 심지어 모든 키를 색인으로 사용하지 않고, 중간중간의 키를 색인으로 사용하면 탐색 하는 키의 절대적인 수가 줄어들고 키는 정렬됨이 보장되어 안전하게 데이터를 찾을 수 있습니다.
각 세그먼트가 정렬됨이 보장되면 우리가 흔히 아는 병합정렬 방식으로 정렬을 수행합니다. 빠른 시간에 데이터를 정렬하면서 동일한 키 값( 로그 구조화 색인에서는 가장 최근 로그를 남기고 나머지를 버리는게 중요 )을 분별하기도 쉽습니다.
위 그림에서 handicap을 찾고 싶다면 handbag에서 다음 색인인 handsome을 보고 “여기 사이에 있겠구나”라는 유추로 다른 키를 보지 않고 바로 원하는 handicap을 찾을 수 있습니다.
어떻게 정렬을 하나?
메모리에서 데이터를 정렬하기 위해서 쓰기 요청이 들어오면 그 값을 균형 트리(ex:레드블랙트리)에 담습니다. 이러한 균형 트리는 값을 정렬해주면서 최소한의 깊이를 유지하기 때문에 탐색이 빠릅니다. 이 균형 트리를 우리는 멤테이블이라고 말합니다.
그러다가 어느 순간 이 트리가 임계치의 용량에 도달하게 되면 트리의 내용을 SS테이블 형태로 변환하여 디스크에 저장합니다. 그리고 새로운 쓰기가 오면 다시 새로운 균형 트리에서 그 값들을 저장하는 것을 반복합니다.
만약 “멤테이블에 원하는 값이 없다면?” 디스크에 있는 SS테이블 형태로 저장 된 세그먼트를 가져와서 읽으면 됩니다. 가장 최근에 저장 한 세그먼트부터 계속해서 읽어나가는 방법으로 원하는 값을 찾게 됩니다.
어디에 사용하지?
정렬 된 파일 병합과 컴팩션 원리를 기반으로 저장소 엔진을 LSM 저장소 엔진이라고 합니다. 이 방식을 사용한 루씬은 LSM 저장소 엔진과 유사한 방식으로 용어 사전을 저장하는 엔진이고, 엘라스틱서치와 솔라에서 이러한 전문 검색 색인 엔진을 사용합니다.
HBASE에서도 LSM 저장소 엔진과 유사한 방식으로 구현되어 있습니다.
성능을 최적화 하기 위해서는?
1. 원하는 키가 없으면 모든 키를 탐색해야 하는 문제
이 문제를 해결하기 위해서는 키가 데이터베이스에 존재하지 않음을 미리 알아야 합니다. 그래서 블룸 필터라는 것을 추가적으로 사용합니다.
2. 컴팩션을 하는 방법
SS테이블을 압축하고 병합하는 순서와 시기를 결정하는 전략이 있습니다. 크게는 사이즈 계층 컴팩션과 레벨 컴팩션을 알아보겠습니다.
사이즈 계층 컴팩션은 상대적으로 더 새로운 SS테이블을 상대적으로 오래 된 SS테이블에 병합하여 유지하는 방식입니다.
레벨 컴팩션은 키 범위를 더 작은 SS테이블로 나누고 오래 된 데이터는 개별적인 레벨로 이동시켜서 유지하는 방식입니다.
기본적으로 LSM 트리는 데이터가 정렬되어 있기 때문에 매우 높은 처리량을 보장한다.
2. B트리
B트리는 일단 키-값을 사용하는 인덱스이며, 범위 질의에 효과적입니다.
B트리를 이용한 인덱싱은 이전의 로그 구조화 인덱싱과는 다르게 고정 된 크기의 블럭과 페이지를 사용해서 인덱스를 저장하고, 한 번에 하나의 페이지를 읽고 쓰기를 합니다.
중요한 점은 각 페이지는 주소나 위치를 이용해 식별 할 수 있다는 점입니다. 그리고 하나의 페이지가 다른 페이지를 참조 할 수 있다.는 점 또한 중요합니다. 특정 페이지를 참조 한다면 그 위치 자체가 어느 값 사이의 범위를 나타 낼 수 있기 때문에 원하는 값의 범위를 조금씩 좁혀 나갈 수 있습니다.
최종적으로 개별 키 ( 리프 페이지 )를 포함하는 페이지에 도달하게 되어 원하는 값을 얻을 수 있게 됩니다.
한 페이지에서 다른 페이지의 참조 하는 수를 분기 계수라고 하고 많은 키가 저장 될 수록 가득 찬 페이지를 둘로 쪼개어 저장하면서, 깊이가 깊어집니다.
신뢰 할 수 있는 B트리를 만들기 위해서
기본적인 B 트리의 쓰기 동작은 새로운 데이터를 디스크 상에 페이지를 덮어쓰는 방식으로 동작합니다. 이렇게 할 수 있는 이유는 페이지의 위치는 고정적이기 때문입니다. 즉 참조되는 주소가 바뀌지 않기 때문에 그냥 덮어써도 유지 되는 것이죠.
하지만 키가 많아지면 분기 해야 합니다. 이 경우에는 2개의 하위 페이지를 만들고 데이터를 저장 한 뒤 상위 페이지에서 이 두 하위 페이지를 참조하도록 설정해야 합니다. 이 과정에서 문제가 발생하면 적절한 참조(고아 페이지 발생)를 갖지 못하고인덱스도 훼손되기 때문에 위험합니다. 그래서 스스로 데이터베이스를 복구하기 위한 쓰기 전 로그를 유지 할 수 있습니다.
또 하나의 문제가 될 수 있는 부분은 동시성문제입니다. 여러 개의 스레드가 동시에 B트리에 접근하게 되면 래치(가벼운 Lock)을 사용해서 구조를 보호하는 방법을 사용합니다.
B 트리 최적화
-
일부 데이터베이스를 쓸 때 복사 방식을 사용하면 덮어 쓰기와 같은 방식의 불이익을 방지합니다. 변경 된 페이지는 다른 위치에 적고 트리에 상위 페이지의 새로운 버전을 만들어서 새로 가리킵니다.
-
페이지의 전체 키를 저장하지 않고 축약해서 사용하면, 트리의 깊이 수준을 낮출 수 있습니다.
-
가능 한 리프 페이지를 디스크 상의 연속 된 공간에 저장하려고 합니다. 하드웨어 측면에서 빠른 읽기를 위한 방법이지만, 데이터가 많으면 유지하기 어렵습니다. LSM은 가능하지만요
-
트리에 포인터를 추가하면, 양쪽 페이지의 참조를 가진다면 상위 페이지를 무시 할 수 있다. ( 명확하게 범위를 확인 할 수 있으니까 )
B트리와 LSM 트리의 비교
저자의 경험상으로 종합한 문장은 “쓰기에서는 LSM이 빠르고 읽기는 B트리가 빠르더라” 라고 합니다. 이유로는 LSM은 디스크에 저장 된 SS테이블들을 읽으면서 키를 탐색해야 하기 때문입니다. 하지만, 일반적으로는 작업부하로 시스템을 테스트해야 합니다.
LSM 트리의 장점
데이터베이스의 쓰기 한 번이 디스크에 여러 번 쓰기를 야기하는 효과를 쓰기 증폭이라고 하는데, B 트리의 경우에는 해당 페이지의 몇 바이트만 바뀌어도 전체 페이지를 다시 써야하는 오버헤드와 데이터를 적을 때 로그에 한 번( 페이지 기록 중 문제 발생시 회복하기 위한 쓰기 전용 로그 ), 트리 페이지에 한 번 적어서 총 2번의 쓰기가 발생합니다.
하지만 LSM 트리는 로그에 1번 적는 것 외에는 쓰기 자체에 대한 오버헤드는 크지 않습니다. 쓰기가 많은 데이터베이스의 성능 병목은 디스크에 쓰는 속도 일 수 있는데, 이 경우에는 쓰기 증폭이 성능 비용이 될 수 있습니다.
무엇보다 데이터를 순차적으로 쓸 수 있도록 컴팩션 된 SS테이블 파일을 쓰기 때문에 디스크 쓰기 측면에서 이득을 얻을 수 있습니다.
압축률에서도 LSM은 SS테이블을 주기적으로 만드는 과정에서 파편화를 없애지만, B트리는 파편화가 발생해서 디스크 공간 일부가 남게 됩니다.
요약하면 다음과 같습니다.
-
B트리는 로그( 회복용 )와 트리 페이지에 총 2번 적기 때문에 오버헤드 발생, 하지만 LSM은 로그 자체에서 컴팩션을 수행하기 때문에 쓰기 증폭이 낮음
-
B트리는 페이지의 참조를 임의 공간을 사용하기 때문에 디스크 쓰기 측면에서 비효율, LSM은 가능한 순차적으로 데이터를 쓸 수 있도록 SS테이블을 관리하기 때문에 디스크가 순차적으로 쓸 수 있어 효율적
-
LSM은 로그를 컴팩션을 수행하고 SS테이블을 만들면서 파편화를 없앰, B트리는 페이지를 나누는 등의 동작을 할 때 파편화 발생하여 디스크 낭비가 발생
LSM의 단점
가장 큰 단점이라면 컴팩션을 수행하면서 발생하는 오버헤드라고 말합니다. 비싼 컴팩션을 하는 과정에서 다른 요청이 대기해야하는 상황이 발생 할 수 있습니다. 디스크의 자원은 한정적인데 컴팩션을 수행하면서 SS테이블을 만들고 디스크에 저장하는데 사용되는 자원이 크다면 이러한 문제가 발생 할 수 있습니다.
두 번째는 너무 높은 쓰기 처리량 입니다. 인 메모리에서 순차적으로 쓰기를 수행한다면 쓰기 속도는 매우 높을 것이라고 생각되는데, 컴팩션이 끝나기도 전에 다음 컴팩션이 수행 될 만큼 큰 쓰기가 동작한다면 아직 디스크 상에 SS테이블 형태의 세그먼트로 저장하지 못한 데이터가 남게 됩니다.
보통 SS테이블 기반의 저장소 엔진이 컴팩션이 쓰기 유입 속도를 따라가지 못해도 속도를 조절하지 않기 때문에 모니터링이 필요합니다.
세 번째는 키 중복입니다. B 트리는 각 색인이 정확히 한 곳에 존재하지만, LSM은 다른 세그먼트에 같은 키가 존재 할 수 있습니다. 정렬 된 문장 중 하나가 겹친다면 키 중복이 일어나겠죠. 따라서 강력한 트랜잭션(안정성)이 필요한 데이터베이스는 B트리 색인이 좋다고 합니다.
3. 기타 색인 구조
기본키 색인
데이터베이스의 가장 기본적인 색인으로 데이터베이스에 따라 로우/문서/정점을 고유하게 식별 할 수 있는 색인입니다. 일반적으로 Clustered Index로 사용됩니다.
여기서 Clustered Index란 테이블 당 1개만 사용가능하고, 물리적인 행을 재배열 하며 리프 페이지가 실제 데이터를 담고있는 가장 빠른 형태의 인덱스입니다.
보조 색인
데이터베이스에서 기본키 색인이 아닌 직접 인덱스를 추가하여 만드는 인덱스를 보조 색인이라고 합니다. 필요에 따라 만들 수 있지만 기본적으로 고유하지 않습니다.
보조색인은 Non Clustered Index로 리프 페이지에는 데이터를 가리키는 참조가 적히게 됩니다.
Clustered Index - Non Clustered Index
보조 색인의 경우에는 리프 페이지에 실제 값을 가리키는 참조를 저장한다고 했습니다. 그래서 문제가 되는 부분은 어디에 참조를 저장하는지입니다.
일반적으로는 힙 파일이라고 부르는 특정 순서없이 값을 저장하지만, 이전의 값보다 큰 값를 저장 할 때는 힙에서 충분 한 공간으로 이동해야하고, 모든 색인이 새로운 힙 위치를 가리키게 하는 등 문제가 발생하기 때문에 때로는 Clustered Index를 사용하여 실제 값을 최대한 활용하는 것이 좋다고 합니다.
커버링 색인을 사용하면, 모든 데이터의 색인을 뒤지지 않고, 저장 된 값을 바로 쓸 수 있습니다.
다중 컬럼 색인
컬럼을 다중 컬럼으로 생성 할 수 있습니다. 하지만 순서가 정렬 된 형태이기 때문에 (성, 이름)으로 색인을 만들었다면, 성으로 데이터를 찾고 이름으로 다음 범위를 좁혀나가지만 이름으로 찾을때는 아무런 필요가 없습니다.
전문 검색
이 부분은 잘 모르지만, 엘라스틱서치로 주로 검색 엔진을 개발하는데 이러한 검색 엔진에서 사용하는 루씬은 SS테이블 기반의 색인을 사용합니다. 이 루씬의 인메모리 색인은 여러 키 문자에 대한 유한 상태 오토마톤? 을 사용해서 특정 편집 거리 내에서의 효율적인 검색 단어를 제공할 수 있다고 합니다.