이 글은 Martin Kleppmann의 데이터 중심 애플리케이션 설계를 읽고 기억하고자 적는 게시글입니다.
9. 일관성과 합의
8장에서 공부 한 내용처럼 분산 환경에서는 많은 골칫거리가 있습니다. 이러한 점을 대처하여 내결함성을 가진 분산 시스템을 구축 할 필요가 있는데, 이번에 그 알고리즘에 대해 알아보았습니다.
내결함성을 보장하는 가장 좋은 방법은 범용 추상화를 구현하여 애플리케이션이 이 보장에 의존하게 하는 것입니다. 예를 들면 트랜잭션이라고 볼 수 있습니다. 트랜잭션 자체가 장애(원자성) 혹은 충돌(독립성) 등을 방지하면서 애플리케이션이 걱정하지 않게 해줍니다.
이러한 방식을 계속 사용해서 분산 시스템에서는 합의라는 추상화를 추가적으로 갖습니다. 어떤 동작이든 모든 노드가 동의하게 하는 것으로써 네트워크 결함 혹은 장애 등에 신뢰성있게 합의가 되면 반영하게 되면 완벽합니다. 매우 어렵지만요.
일관성
이전에 비동기적 분산 데이터베이스는 최종적 일관성을 갖는 것으로 만족한다고 알 고 있습니다. 이 뜻은 데이터를 저장했을 때 바로 데이터를 읽을 수 있는지는 명확하지 않지만 결국에는 데이터가 성공적으로 입력 될 것이라고 생각하는 것이라고 공부했습니다.
이러한 약한 보장은 시스템에 결함이 있거나, 동시성이 높을 때 문제가 발생 할 수 있다고 합니다.
선형성
최종적 일관성을 약한 보장이라고 말했다면, 반대로 강한 보장이 등장해야 합니다.
데이터를 쓰고 난 후 읽었을 때 해당 데이터를 무조건 읽을 수 있는 것을 보장하는 단계가 바로 선형성입니다. 그리고 이러한 동작의 조건으로 데이터 복사본이 하나만 존재하는 것 처럼 보이면 된다고 합니다.
이해하기 쉽게 A 저장소만 있다면 모든 유저가 A에서만 읽고 쓰기 때문에 항상 같은 결과를 읽을 거라는 이야기입니다.
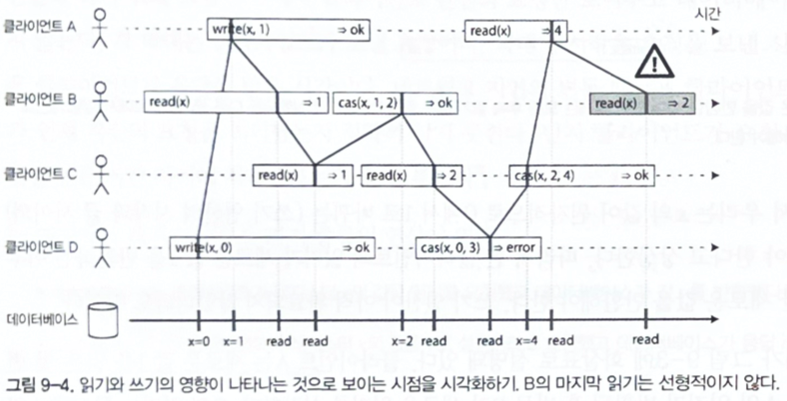
그림은 선형성에 대해 명확하게 나타내고 있습니다. 각 읽기가 동작 할 때 쓰기의 어느 시점에 쓰여지는지는 명확하지 않기 때문에 쓰기 연산의 전후 값 중 어떤 값이 나올지는 모르지만, 적어도 이전에 반영 된 새로운 값이 읽어졌다면, 이후의 읽기에서도 반영 된 새로운 값이 등장해야 한다는 의미입니다.
헷갈릴 수 있는 특성인 직렬성은 트랜잭션이 같은 객체에 접근 할 때 독립적으로 연산하여 어느 순서에 따라 동작하도록 보장하는 특성이 있는데, 여기서는 정확한 순서를 보장하지 않기 때문에 요청의 순서에 따라 동작하는 선형성보다는 약한 형태입니다.
1. 선형성이 필요한 곳
1) 잠금
데이터를 잠금에 있어서 선형성은 필요합니다. 왜냐하면 잠금이 선형적이지 않으면, 점유하고 있는 데이터에 대해 다른 노드가 접근 할 수 있고 이로인해 데이터가 유실 될 가능성이 있습니다.
2) 리더 선출
리더 선출에 선형성이 보장되지 않는다면, 리더가 여러 개인 스플릿 브레인 현상이 발생하고 이 경우 마찬가지로 데이터가 덮어씌워지는 등 데이터 유실이 발생 할 수 있습니다.
3) 제약조건과 유일성 보장
만약 유저의 고유 ID와 같은 특정 ID에 대해서 유일성을 보장해야 한다면 선형성은 필수적입니다. 혹은 은행 계좌의 프로그램은 음수가 되지 않아야하는 제약조건을 엄중하게 관리 할 필요가 있습니다. 이런 경우에도 선형성이 필수적입니다.
4) 채널 간 타이밍 의존성
어려운 말이지만 결국 다음 동작 전 이전까지의 데이터가 정확하게 입력 되어야 한다는 것입니다. 예를 들면 관련 상품을 추천해주는 알고리즘은 유저의 최근 조회 상품 정보를 입력 받아야 결과를 낼 수 있다고 할 때, 알고리즘 시작 전 조회 정보가 입력되어 있어야 합니다.
2. 선형성 구현
내결함성을 갖기 위해 복제를 채택하는 방식중에서 선형성관 연관지어 보면 다음과 같습니다.
- 단일 리더 복제 - 동기식이면 선형성을 가질 수 있음
- 합의 알고리즘 - 선형적
- 다중 리더 복제 - 비선형적
- 리더 없는 복제 - 시간을 이용해도 타임스탬프가 밀릴 수 있고, 느슨한 정족수는 비선형적일 가능성이 높음
3. 선형성의 비용
들으면 들을수록 선형성은 장점만 있는 것 같지만 어느정도의 트레이드 오프는 감안해야 합니다. 선형적인 애플리케이션인 단일 복제 노드는 팔로워 노드와 리더 노드와의 연결이 끊기면 팔로워 노드에 접근한 클라이언트는 새로 쓰여진 데이터에 접근 할 수 없습니다.
하지만 비선형적인 다중 복제의 경우에는 다른 데이터센터에서 독립적으로 데이터를 다루기 때문에 이러한 문제에 강합니다.
즉 선형적인 프로그램은 (네트워크 장애의 발생 가능성이 있는 한) 가용성이 없다고 말할 수 있습니다. 또한 선형적인 프로그램은 성능도 상대적으로 낮습니다
순서화
순서화는 연산이 잘 정의 된 순서대로 실행됨을 말하며 이는 곧 순서화가 선형성의 기반이라는 것을 알 수 있습니다. 그리고 순서화는 인과성을 보존해주기도 합니다.
여기서 인과성은 쉽게 말하면 질문에 대한 답은 질문을 듣고 나서 할 수 있다는 말로 생각할 수 있습니다. 누구든 A라는 결과를 볼 수 있었다면 다른 사람들도 A라는 결과를 볼 수 있어야 합니다.
인과성에는 한계점이 있는데 전체 순서를 정할 수 없다는 점입니다. A와 B가 모두 비교 할 수 있는 지표라면 쉽게 순서를 정할 수 있지만, 비교 할 수 없다면 순서를 정할 수 없습니다.
순서화를 보장하는 방법
비교하여 무엇이 먼저인가를 얻기 위한 방법은 비교 가능한 값을 사용하는 방식이 있습니다. 가장 대표적으로 사용하는 값은 일련번호 혹은 타임스탬프 정도라고 볼 수 있을 것 같네요.
단일 리더가 아닌 다중 리더나 리더가 없는 방식에서도 적용 할 수 있는 방법이 있습니다.
- 짝수와 홀수 일련번호를 별도로 받는 노드 구성
- 물리적 시계에서 얻은 타임스탬프 사용
- 일련번호 범위를 미리 정의
어떠한 조건으로 순서대로 동작함은 보장할 수 있지만 인과성을 갖지는 않습니다. 무엇이 먼저인지 알 수 없으니까요.
램포트 타임스탬프
램포트 타임스탬프는 ( 카운터, 노드 ID )로 이루어진 세트를 이용해서 순서를 보장하면서 인과성을 갖도록 개발 할 수 있습니다.
여기서 가장 큰 전제는 카운터가 크면 타임스탬프가 크고, 카운터가 같으면 노드ID가 크면 타임스탬프가 크다는 사실입니다. 결국 어떻게든 최신의 데이터를 찾을 수 있습니다.
어떤 문제든 순서를 정할 수 있을 것 같은 이 방식도 문제는 있습니다. 바로 사후 판별적인 느낌이 강하기 때문입니다. 즉각적인 서비스에서는 이러한 타임스탬프를 기반으로 동작하기에는 오랜 대기시간을 유발 할 수 있습니다.
분산 환경에서는 전체 순서 브로드캐스트를
단일 환경이라면 CPU의 실행 순서가 곧 순서이지만, 분산 환경에서는 순서를 정하는게 매우 어렵고, 램포트 타임스탬프로도 문제가 해결되지 않기 때문에 전체 순서 브로드캐스트와 같은 방식을 사용합니다.
전체 순서 브로드캐스트는 한 노드에 메시지가 전달되면 모든 노드에 전달됨을 보장하고 모든 노드에 같은 순서로 전달됨을 보장합니다. 그 메시지 앞에 다른 메시지가 끼어드는 것을 막아버리죠. 이러한 방식으로 펜싱 토큰과 같이 락을 걸어주기도 합니다.
선형성은 최근에 쓴 값을 읽을 수 있음을 보장해야 하기 때문에 완전한 선형성은 아니지만, 적어도 모든 노드가 메시지를 받음을 보장하기 때문에 순서와 인과성은 보장합니다.
합의
합의는 여러 노드들이 무언가에 동의하는 동작을 말합니다. 여기서 무언가는 리더를 선출하는 행동일 수 있고 어떠한 동작을 완료 했음을 확인하는 동작 일 수 있습니다.
분산 환경에서 겪을 수 있는 문제 중 우리가 알아 본 내용으로는 다음과 같이 두 가지가 있습니다.
- 스플릿 브레인 - 기존 리더 노드의 장애등의 문제로 리더가 2개 이상이 되는 문제
- 원자적 커밋 - 트랜잭션이 어느 노드에서는 성공하고 어느 노드에서는 실패했지만, 정확한 결과를 얻기 위해서는 둘 다 커밋하거나 어보트시키는 동작이 필요한 상황
원자적 커밋과 2단계 커밋 (2PC)
원자적 커밋은 각 노드의 트랜잭션이 성공 혹은 실패를 했을 때 데이터가 정확히 원하는 형태로 저장되지 않을 수 있는 문제입니다. 정확하게 원하는 동작을 수행하기 위해서는 일단 어느 하나의 노드라도 실패하면 모든 노드에서 어보트를 수행해야 합니다. 적어도 선형성을 요구하지 않는 상태의 복제 노드가 아니라면요.
2단계 커밋은 이러한 문제를 명확하게 해결 할 수 있는 방법입니다. 여기에서는 코디네이터라는 단어가 나옵니다. 가장 대표적인 코디네이터는 주키퍼가 있습니다.
코디네이터는 각 노드에게 순서가 보장되는 전체 순서 브로드캐스트를 요청함으로써 각 노드가 커밋을 할 준비가 되어 있는지, 혹은 실패해서 어보트를 실행해야 하는지를 물어봅니다. 만약 모든 노드가 커밋을 할 준비가 되면 그때 코디네이터는 커밋을 수행하도록 요청을 보내면서 정상적인 동작을 유도합니다.
이렇게 유연성을 추가하더라고 돌아오지 못하는 지점이 있습니다. 각 노드는 상태와 상황에 따라서 자유롭게 커밋이나 어보트를 발생시킬 수 있지만, 일단 의사를 표현 한 순간부터 변경 할 수 없습니다. 그리고 모든 노드가 커밋을 합의한 이후부터는 이 결정을 바꿀 수 없습니다. 즉 일단 합의 된 내용은 중간에 변경 할 수 없습니다
코디네이터가 죽어버리면?
2PC도 치명적인 문제가 하나 있습니다. 바로 커밋을 하기로 합의 되었음을 각 노드에게 메세지를 전달하는 과정에 죽으면 각 노드가 합의 되었다는 내용을 알 수 없다는 점이죠. 이 경우에 그저 메세지 전송을 재실행하거나 코디네이터가 깨어나기를 기다리는 것은 큰 의미가 없을 수 있습니다.
이러한 문제를 해결하기 위해 3PC의 방법은 있지만, 성능과 같은 문제로 인해 잘 사용하지는 않는다고 합니다.
단일 리더 복제에서의 합의
전체 순서 브로드캐스트는 모든 노드가 같은 순서로 메시지를 받는 방식임을 공부했습니다. 그리고 이 방식으로 동일한 순서로 합의를 할 수 있기에 모두가 인정하는 결정을 내릴 수 있음을 알고 있습니다.
단일 리더 복제에서 모든 쓰기를 팔로워에게 전달하고 같은 순서로 쓰도록하는 동작도 마찬가지 입니다. 이 과정에서도 전체 순서 브로드캐스트가 사용되는데, 여기서 문제가 있습니다. 바로 단일 리더 복제에서 리더를 선출하는 것 또한 합의가 필요하다는 점 입니다.
결국 팔로워에게 복제를 전달하는 메시지를 전달해서 합의를 하는 과정을 위한 리더를 선출하는 과정도 합의가 필요하다는 뜻으로 리더 선출에서 합의에 문제가 생기면 복제를 위한 합의도 이루어지지 않는다는 뜻입니다.
리더 노드에 번호 붙여서 리더 선출
리더가 죽으면 우리는 새로운 리더를 선출합니다. 그때 리더에 순차적인 번호를 적고 죽었던 리더가 부활해서 리더 권한을 사용하려할때 나보다 높은 번호의 리더가 있는지를 확인하면 문제가 해결됩니다.
그리고 리더 노드가 하는 결정에 대해서 정족수(어느정도의 노드의 수)의 팔로워 노드가 해당 결정에 대해서 동의를 해야 결정을 이행 할 수 있습니다.
코디네이터 ( 주키퍼 )
지금까지 알아본 코디네이터는 펜싱 토큰과 같은 동작으로 분산 환경에서 특정 자원에 대한 연산을 정상적으로 할 수 있도록 도와주고, 2PC와 같이 합의가 필요한 결정에 대해서 커밋과 어보트를 트랜잭셔널하게 할 수 있도록 도와주고, 리더 선출에 있어서 마찬가지로 합의를 할 수 있도록 도와준다고 배웠습니다.
거기에 추가적인 내용으로 주키퍼는 작은 양의 인메모리 저장공간을 가지고 팔로워 노드로의 복제를 전체 순서 브로드캐스트로 수행하도록 도와줍니다.
추가적인 기능은 더 있습니다.
- 선형적 원자적 연산 - 동시에 수행되는 연산에 대해서 원자적이고 선형적으로 수행되도록 도와줍니다.
- 연산의 순서화 - 모든 연산에 단조 증가하는 트랜잭션 ID와 버전 번호를 사용해서 연산을 순서화 합니다.
- 장애 감지 - 노드와 수명이 긴 세션을 유지하면서 하트비트를 교환해서 생존 유무를 확인하고, 타임아웃보다 길게 하트비트를 받지 못하면 죽었다고 간주합니다.
- 변경 알림 - 노드 간의 변경 사항이나 생성 한 잠금이나 값등을 알 수 있습니다.
또한 분산 환경으로 노드가 나누어져있고, 각 클러스터가 다른 IP를 가지고 있을 떄 어느 IP로 연결해야 하는지를 알려주는 서비스 찾기의 역할도 수행하고 있습니다.